Building Vector Search with Redis: From Embeddings to Semantic Retrieval
End-to-end guide for building semantic search and retrieval systems on Redis using embeddings, RediSearch vector fields, and practical production tips.
End-to-end guide for building semantic search and retrieval systems on Redis using embeddings, RediSearch vector fields, and practical production tips.
Comprehensive guide to Redis Stack modules with practical patterns, deployment examples, tuning advice, client snippets, and migration tips.
Learn how to use PostgreSQL with pgvector for AI applications. Explore vector similarity search, hybrid queries, and building RAG systems using the world's most popular open-source database.
Learn how to design databases for Retrieval-Augmented Generation systems. Explore data pipelines, storage strategies, and infrastructure patterns for production RAG applications.
Explore how vector databases power AI applications in 2026. Learn about vector search, embedding storage, and how Pinecone, Weaviate, Qdrant, and Milvus compare for production RAG systems.
Implement vector search in PostgreSQL for AI applications. Learn pgvector, embedding generation, similarity search, and building RAG systems with your existing database.
Master database migration strategies including schema migration, data migration, and zero-downtime migrations. Learn tools, patterns, and best practices for moving between database systems safely.
Learn how to use Meilisearch for AI applications. Build semantic search, RAG pipelines, vector databases, and intelligent applications with LLMs.
Explore the latest Meilisearch developments in 2025-2026. Learn about vector search, cloud offerings, multi-language support, and the evolving search ecosystem.
Discover production-ready Meilisearch implementations. Learn patterns for e-commerce, documentation, mobile apps, multi-tenant systems, and geo-search.
Explore Meilisearch's internal architecture. Understand the inverted index, BM25 algorithm, tokenization, caching, and how Meilisearch achieves lightning-fast search.
Learn how to deploy, configure, and maintain Meilisearch in production. Covers deployment strategies, security, monitoring, backup, and performance optimization.
Learn Meilisearch from installation to advanced search features. Complete guide covering indexing, typo tolerance, filters, and real-world applications.
Learn how to use MongoDB for AI applications. Build semantic search, RAG pipelines, vector databases, and ML feature stores.
Explore MongoDB's latest developments in 2025-2026. Learn about MongoDB 8.0, Atlas serverless, vector search, and multi-cloud deployments.
Discover production-ready MongoDB implementations. Learn patterns for web apps, mobile, IoT, content management, and real-time analytics.
Explore MongoDB's internal architecture. Learn about WiredTiger storage engine, B-Tree indexes, journaling, and query execution.
Learn MongoDB operations including replica sets, sharding, backup, security, and monitoring. Complete guide for production deployments.
Learn MongoDB from installation to advanced queries. Complete guide covering document model, CRUD operations, indexing, and data modeling.
Master database performance optimization including query analysis, indexing strategies, configuration tuning, and caching strategies for MySQL and PostgreSQL.
Master database indexing including B-tree, hash indexes, composite indexes, vector indexes for AI, and optimizing query performance in PostgreSQL, MySQL, and cloud databases.
Master vector databases for AI applications, semantic search, and similarity matching. Learn about pgvector, Pinecone, Weaviate, and implementation patterns.
Master Apache Cassandra from installation to CQL queries. Learn data modeling, partition keys, and Cassandra Query Language with practical examples.
Master Apache Solr from installation to advanced queries. Learn document indexing, Solr schema, search syntax, and query parameters.
Explore Cassandra 5.0 features: vector search capabilities, improved performance, security enhancements, and the evolving Cassandra ecosystem.
Learn how Cassandra powers AI applications: time-series data storage, feature stores, real-time analytics, and high-throughput ML data pipelines.
Discover how Cassandra powers production systems: IoT platforms, messaging, user activity tracking, gaming, and financial applications with practical examples.
Deep dive into Cassandra architecture. Understand gossip protocol, Memtable, SSTable, compaction, and tunable consistency internals.
Learn Cassandra administration: node operations, backup strategies, repair procedures, monitoring with nodetool, and production cluster management.
Learn how to use ClickHouse for AI applications. Build vector similarity search, RAG pipelines, and ML feature engineering with ClickHouse.
Deep dive into ClickHouse internals. Understand the MergeTree storage engine, columnar storage, query processing pipeline, and architectural decisions.
Master ClickHouse operations including cluster setup, replication, backup strategies, performance tuning, and production deployment patterns.
Explore the latest ClickHouse developments in 2025-2026. Learn about vector similarity search, AI integration, performance improvements, and cloud-native features.
Explore practical ClickHouse use cases including web analytics, IoT, logging, and production deployments. Learn patterns and implementation strategies.
Master ClickHouse from basics. Learn data types, SQL queries, table engines, installation, and practical examples for real-time analytics.
Learn how to use DuckDB for AI applications. Build vector search, ML feature engineering, and RAG pipelines with DuckDB and the vss extension.
Deep dive into DuckDB internals. Understand vectorized execution, columnar storage, query processing pipeline, and the architectural decisions behind DuckDB's performance.
Master DuckDB operations including configuration, memory management, query optimization, backup strategies, and production deployment patterns.
Explore the latest DuckDB developments in 2025-2026. Learn about new features, extensions, performance improvements, and the growing DuckDB ecosystem.
Explore practical DuckDB use cases including data analysis, ETL, business intelligence, and production deployments. Learn patterns and implementation strategies.
Master DuckDB from basics to advanced analytics. Learn SQL for OLAP, data types, queries, installation, and practical examples for data analysis.
Learn the fundamentals of InfluxDB including measurements, tags, fields, line protocol, InfluxQL queries, and data modeling for time-series applications.
Leverage InfluxDB for AI applications including time-series forecasting, anomaly detection, feature engineering, and ML model training pipelines.
Deep dive into InfluxDB architecture: TSM storage engine, compression, shards, WAL, query execution, and performance characteristics.
Master InfluxDB operations including installation, configuration, backup, monitoring, high availability, and production best practices.
Explore the latest InfluxDB developments including InfluxDB 3.0, InfluxDB Cloud, new features, and the evolving time-series database landscape.
Explore real-world InfluxDB use cases including IoT monitoring, DevOps observability, financial analytics, industrial IoT, and application performance tracking.
Learn how to use MariaDB for AI applications. Build vector search, RAG pipelines, and AI solutions with MariaDB Vector and enterprise features.
Deep dive into MariaDB internals. Understand storage engines (InnoDB, Aria, ColumnStore), query processing, caching, and the unique architectural decisions in MariaDB.
Master MariaDB operations including backup strategies, replication setup, performance optimization, Galera Cluster configuration, and production deployment.
Explore the latest MariaDB developments in 2025-2026. Learn about vector search, AI integration, performance improvements, and emerging capabilities in MariaDB 11.8 LTS.
Explore practical MariaDB use cases including web applications, e-commerce, analytics, IoT, and AI applications. Learn production patterns and implementation strategies.
Master MariaDB from basics to advanced usage. Learn data types, SQL operations, storage engines, replication, and practical development with MariaDB.
Learn the fundamentals of MinIO including buckets, objects, S3 API, access keys, and basic operations for cloud-native object storage.
Leverage MinIO for AI applications including ML data lakes, training data storage, model artifacts, vector databases, and end-to-end ML pipelines.
Deep dive into MinIO architecture: erasure coding, distributed hashing, quorum consensus, the storage engine, and performance characteristics.
Master MinIO operations including distributed deployment, erasure coding, replication, monitoring, security, and production best practices.
Explore the latest MinIO developments including S3 API enhancements, Kubernetes CSI, performance improvements, and the evolving object storage landscape.
Explore real-world MinIO use cases including data lakes, backup and recovery, media storage, analytics, healthcare imaging, and IoT data pipelines.
Explore MySQL 8.0 and 8.4 LTS features: window functions, CTE, JSON enhancements, roles, instant ADD COLUMN, and migration from MySQL 5.7.
Comprehensive guide to using MySQL for AI workloads including vector embeddings, JSON document storage, ML model management, and production AI pipelines.
Discover how MySQL powers production systems: web applications, e-commerce, CMS, logging, analytics, and multi-tenant SaaS with practical examples.
Deep dive into MySQL architecture. Understand InnoDB storage engine, buffer pool, MVCC, query execution, and transaction management internals.
Learn MySQL administration: backup strategies, point-in-time recovery, replication, MySQL InnoDB Cluster, ProxySQL, and production monitoring.
Master MySQL from installation to advanced queries. Learn data types, constraints, indexes, and SQL operations with practical examples.
Learn the fundamentals of Neo4j including nodes, relationships, labels, properties, and Cypher query language for graph data modeling.
Leverage Neo4j for AI applications including knowledge graph construction, vector embeddings, GraphRAG pipelines, and machine learning feature engineering.
Deep dive into Neo4j architecture: storage engine, property files, relationship traversal, indexes, caching, and query execution pipeline.
Master Neo4j operations including installation, configuration, backup, recovery, monitoring, clustering, and production best practices.
Explore the latest Neo4j developments including version 5.x features, GraphRAG, multi-database support, graph machine learning, and the evolving graph ecosystem.
Explore real-world Neo4j use cases including social networks, fraud detection, recommendation engines, network management, and knowledge graphs.
Explore OpenSearch versions 2.x and 3.x: vector search, performance improvements, security enhancements, and the evolving ecosystem.
Comprehensive guide to using OpenSearch for AI applications including k-NN vector search, RAG pipelines, embedding storage, hybrid search, and production best practices.
Discover OpenSearch production use cases: log analytics, application search, security analytics, business intelligence, and observability.
Deep dive into OpenSearch architecture. Understand Apache Lucene, segment-based storage, sharding, replication, and near real-time search internals.
Learn OpenSearch administration: index management, snapshots, cluster scaling, performance tuning, and security configuration.
Master OpenSearch from installation to advanced queries. Learn OpenSearch DSL, index management, mappings, and search operations with practical examples.
Explore PostgreSQL 17 and 18: vector search, JSON enhancements, performance improvements, logical replication advances, and the growing extension ecosystem.
Learn how PostgreSQL powers AI applications with pgvector, vector similarity search, RAG pipelines, embedding storage, and hybrid search for LLM applications.
Discover how PostgreSQL powers production systems: e-commerce, fintech, data warehousing, GIS, time-series, and multi-tenant applications with practical examples.
Deep dive into PostgreSQL architecture. Understand MVCC, WAL, query planning, storage engine, and transaction management internals.
Learn PostgreSQL administration: backup strategies, point-in-time recovery, replication, high availability, connection pooling, and production monitoring.
Master PostgreSQL from installation to advanced queries. Learn data types, constraints, indexes, and SQL operations with practical examples.
Compare Dragonfly, KeyDB, Memcached, DynamoDB, and other alternatives to Redis. Learn when to choose alternatives for specific use cases.
Learn how Redis powers AI applications with vector search, semantic caching, RAG pipelines, and LLM session management. Complete implementation guide.
Explore the latest Redis developments including Redis 8.0, vector search, Redis Stack, cloud offerings, and how the ecosystem is evolving for AI applications.
Deep dive into Redis internals. Understand SDS, SkipList, QuickList, Hash tables, event loop, and persistence algorithms that power Redis performance.
Discover practical Redis implementations for caching, session management, message queues, rate limiting, and distributed systems with code examples.
Master Redis from scratch. Learn key-value concepts, 5 data types, persistence strategies, and practical commands for modern application development.
Explore Solr 9.x features: vector search, security improvements, cloud capabilities, and the evolving Solr ecosystem.
Comprehensive guide to using Apache Solr for AI applications including vector similarity search, RAG pipelines, embedding storage, and hybrid search capabilities.
Discover Solr production use cases: e-commerce search, enterprise search, site search, and document retrieval with practical implementations.
Deep dive into Solr architecture. Understand Apache Lucene, inverted index, segment merging, query execution, and caching internals.
Learn Solr administration: collection management, backup strategies, monitoring, security, and production performance tuning.
Learn how to use SQLite for AI applications. Build vector search, RAG pipelines, and local AI solutions with sqlite-vec and embeddings.
Deep dive into SQLite internals. Understand B-Tree storage, WAL mode mechanics, query processing pipeline, and MVCC implementation.
Master SQLite operations including backup strategies, performance optimization, WAL mode configuration, and production deployment best practices.
Explore the latest SQLite developments in 2025-2026. Learn about new features, vector search capabilities, enhanced JSON support, and emerging use cases.
Explore practical SQLite use cases including mobile apps, IoT, caching, analytics, and AI applications. Learn production patterns and implementation strategies.
Master SQLite from basics to advanced usage. Learn data types, SQL operations, performance optimization, and best practices for embedded database development.
Learn the fundamentals of TimescaleDB, including hypertables, chunks, time_bucket, and core SQL operations for time-series data management.
Leverage TimescaleDB for AI applications including feature engineering, time-series forecasting, vector embeddings storage, and ML model training pipelines.
Deep dive into TimescaleDB internals: hypertable architecture, chunk management, query planning, compression, and the底层 implementation details.
Master TimescaleDB operations including installation, configuration tuning, backup strategies, monitoring, replication, and production best practices.
Explore the latest TimescaleDB developments including version 2.16+, columnstore support, performance improvements, and the evolving time-series database landscape.
Explore real-world TimescaleDB use cases including IoT monitoring, financial analysis, DevOps observability, industrial IoT, and application performance tracking.
Comprehensive guide to Drizzle ORM - learn about type-safe SQL, lightweight footprint, and how it compares to Prisma. Build faster applications with Drizzle.
Comprehensive guide to Supabase - learn how to build scalable backends with PostgreSQL, authentication, real-time subscriptions, storage, and edge functions. The open source alternative to Firebase.
Comprehensive guide to Turso and LibSQL - learn about edge-hosted SQLite, embedded replicas, and how to build globally distributed applications with simple, portable database.
A comprehensive guide to ACID and BASE consistency models, CAP theorem, and how to choose the right database for your application
A comprehensive guide to database indexing - understand B-Tree, hash, GIN, GiST indexes and how to optimize query performance
A comprehensive guide to database replication - understand replication types, conflict resolution, and building resilient database architectures
A comprehensive guide to distributed transactions - understand 2PC, 3PC, TCC, Saga pattern, and modern frameworks like Seata for cross-service data consistency
A comprehensive guide to NewSQL databases - understand distributed SQL, horizontal scaling, and ACID compliance
A comprehensive guide to vector databases - understand embeddings, similarity search, and how to choose the right vector database for AI applications
Master analytics engineering with dbt, Looker, and Tableau. Learn data modeling, transformation pipelines, visualization best practices, and building self-service analytics infrastructure.
Master data governance with lineage tracking, cataloging, and access control. Learn data catalog implementation, column-level security, governance frameworks, and building trusted data assets.
Master data privacy with PII detection, masking, and anonymization. Learn GDPR/CCPA compliance, privacy-preserving techniques, and building secure data pipelines.
Master data warehouse cost optimization. Learn storage tiering, compute scaling, query optimization, and reducing cloud data warehouse costs by 60%+.
Master data warehouse optimization with Snowflake, BigQuery, and Redshift. Learn query performance tuning, clustering, partitioning, cost optimization, and building high-performance analytical systems.
Complete comparison of ETL vs ELT approaches. Learn when to use each pattern, modern data stack tools, transformation strategies, and building efficient data pipelines.
Master real-time analytics with streaming aggregations and OLAP. Learn Apache Flink, Kafka Streams, ClickHouse, and building low-latency analytical systems.
Master vector search at scale for semantic search. Learn embedding generation, vector databases, similarity search, and building production-grade semantic search systems.
Complete guide to data lakehouse architecture. Learn Delta Lake, Apache Iceberg, data governance, and real-world implementation patterns.
Build robust data observability by integrating Great Expectations with dbt. Learn how to combine validation frameworks with transformation tools for production-grade data quality.
Complete guide to database high availability and failover strategies. Learn replication, failover mechanisms, and real-world deployment patterns.
Complete guide to graph databases for relationship-heavy data. Learn Neo4j, ArangoDB, and graph query patterns with practical examples and performance optimization.
Comprehensive comparison of MongoDB Atlas, Azure CosmosDB, and AWS DocumentDB for managed NoSQL databases. Includes pricing analysis, feature comparison, migration guides, and real-world scenarios.
Complete guide to MongoDB sharding for scaling to billions of documents. Learn shard key selection, rebalancing, and real-world deployment strategies.
Complete guide to advanced PostgreSQL features. Learn table partitioning, JSONB operations, window functions, and performance optimization techniques for handling millions of records.
Complete guide to query optimization and indexing for large datasets. Learn index types, query analysis, and real-world optimization techniques for handling millions of records.
Build production real-time data pipelines using Kafka, Apache Flink, and Spark Streaming. Covers architecture, implementation, scaling, and best practices for streaming data processing.
Complete guide to time series databases for metrics and monitoring. Learn InfluxDB, TimescaleDB, and Prometheus with practical examples and optimization strategies.
Complete guide to vector databases for semantic search and AI applications. Learn Pinecone, Milvus, Weaviate with practical examples, embeddings, and real-world use cases.
Explore how AI search engines are revolutionizing information discovery. Learn what they are, how they differ from traditional search, key features, current examples, and their impact on the future of online search.
Comprehensive guide to open-source AI search engines and vector databases. Compare solutions for implementing semantic search, multimodal search, and AI-powered retrieval in your applications.
Comprehensive guide to database design principles and migration strategies. Learn normalization, indexing, schema versioning, and zero-downtime migrations.
Comprehensive guide to SQLAlchemy and ORM design patterns. Learn Core vs ORM, Active Record, Data Mapper, Repository patterns, and best practices.
Understanding ACID properties, isolation levels, and consistency models in distributed systems
Fuzzy search using regular expressions is a common requirement in apps that let users search for names, titles, slugs, or other short text fields. …
If you have a Go struct like this:
type Student struct {
Name string `bson:"name"`
Age int `bson:"age"`
}
Say there are many student …
Database access is fundamental to web services, yet it’s often a source of bugs, security vulnerabilities, and performance issues. …
Database performance is often a bottleneck in production Rust applications. Slow queries compound at scale—what works fine for 100 concurrent users …
A guide to using MongoDB with JavaScript, covering basics, CRUD operations, and best practices for Node.js developers.
MongoDB is a document-based database that stores data in JSON-like format. It is schema-less and primarily handles JSON documents. …
Meilisearch is a fast, open-source search engine. This guide provides scripts to start and stop Meilisearch manually. For production use, …
Connect to replica set m103-repl, to secondary
mongo --port 27004 --authenticationDatabase admin -u m103-admin -p m103-pass
to primary …
复制让多台服务器拥有同样的数据副本,每一台服务器都是其他服务器的镜像,而每一个分片都有其他分片拥有不同的数据子集。
分片的目标之一是创建一个拥有多个实例(或多台机器)的目标集群,整个集群对应用程序来说就像是一台单机服务器。
为了对应用程 …
M103: MongoDB Cluster Administration: The Mongod
$match and $project$match: Filtering documentsdb.solarSystemaggregate([{$match: {}}])
$match uses standard MongoDB …
$addFields and how it is similar to $project// reassign ``gravity`` field value
db.solarSystem.aggregate([{"$project": { "gravity": …connet to Atlas Cloud
mongo …db.companies.findOne()
db.companies.createIndex({'description': 'text', …$redact StageRestricts the contents of the documents based on information stored in the documents themselves.
// creating a variable to refer …Index usage
Memory Constraints
Realtime processing(online application)
Batch processing(offline analytics)
What problem do indexes try to solve?
Slow queries
Think about a book index.
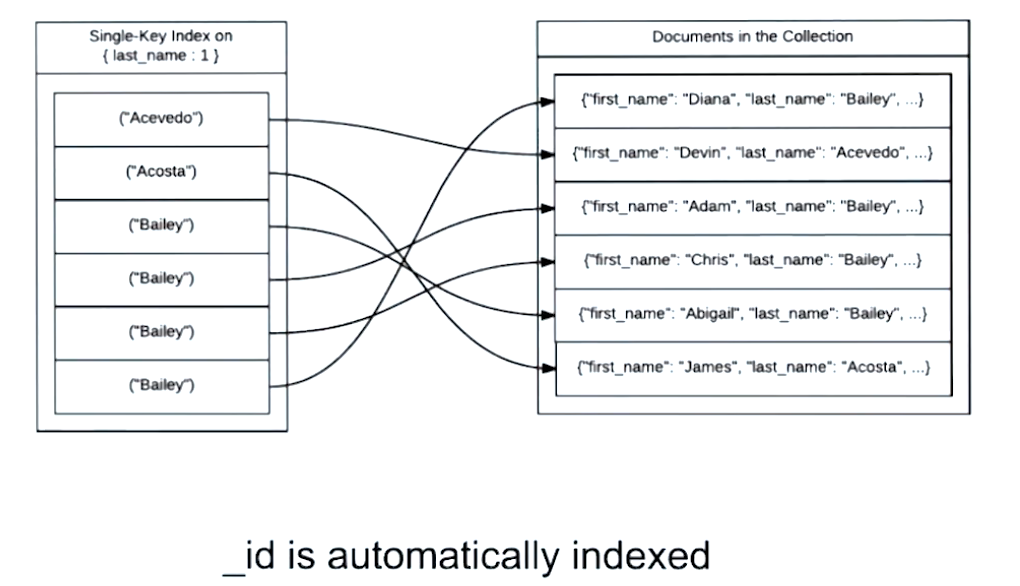
B-tree …
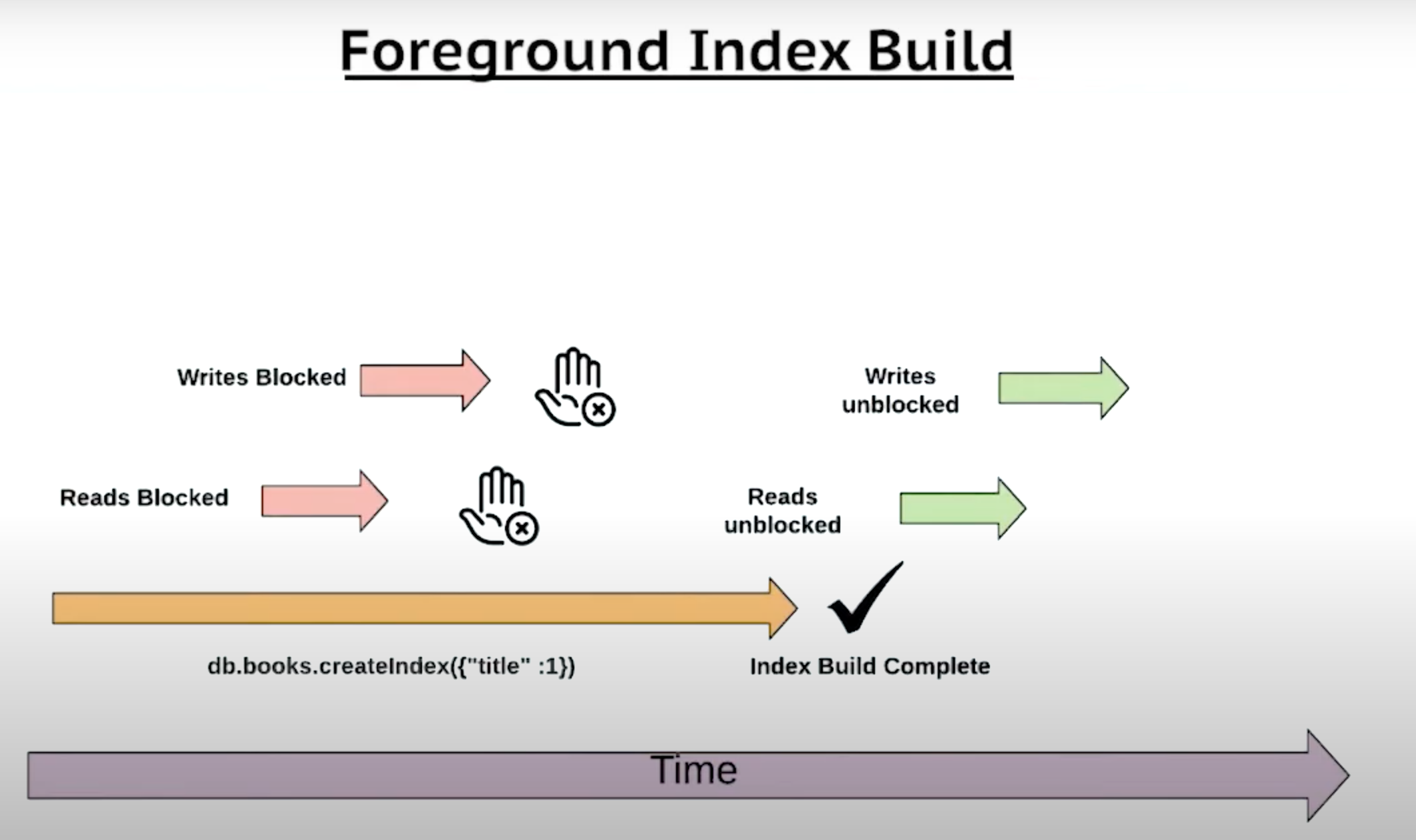
Hybrid Index Build(new in 4.2)
db.movies.createIndex({title: 1})
db.movies.createIndex({title: 1}, {background: true})
// use the m201 database
use m201
// create an …sort()
limit(numPerPage)
skip(page*numPerPage)
Upsert == Insert + Update
insertOne()
insertMany()
const upsertResult = await …$lookupWhat to do:
Application Resilience & Robustness
Connection pooling is all about reusing database connections. …
Build an application: mflix
Good performance
Maximizing the productivity of your developers
Minimizing the overall costs of your solution …
One customer -> (One to many) Many Invoices
Invoices <- (Many to Many) -> Products
Should the information be embedded or …
Patterns(设计模式) are for data modeling and schema design.
Use this pattern if you need to compute similar computations many times.
Scenario
We built a very successful navigation application for cell phones. The application has been installed on many devices throughout the …
Sqlite3 Commands
MongoDB
Comprehensive guide to MySQL performance monitoring using SHOW VARIABLES and SHOW STATUS commands with practical examples and best practices.
删除foo 集合中所有文档?
db.foo.remove()
db.foo.drop()
db.mailing.list.remove({"opt-out": true})
Types of Indexes in MySQL