connet to Atlas Cloud
mongo "mongodb://cluster0-shard-00-00-jxeqq.mongodb.net:27017,cluster0-shard-00-01-jxeqq.mongodb.net:27017,cluster0-shard-00-02-jxeqq.mongodb.net:27017/aggregations?replicaSet=Cluster0-shard-0" --authenticationDatabase admin --ssl -u m121 -p aggregations --norc
The $group Stage
grouping by age and getting a count per age using {$sum: 1} pattern
db.customers.aggregate({$group: { _id: "$age", total: {$sum: 1}}})
// grouping by year and getting a count per year using the { $sum: 1 } pattern
db.movies.aggregate([
{
"$group": {
"_id": "$year",
"numFilmsThisYear": { "$sum": 1 }
}
}
])
// grouping as before, then sorting in descending order based on the count
db.movies.aggregate([
{
"$group": {
"_id": "$year",
"count": { "$sum": 1 }
}
},
{
"$sort": { "count": -1 }
}
])
// grouping on the number of directors a film has, demonstrating that we have to
// validate types to protect some expressions
db.movies.aggregate([
{
"$group": {
"_id": {
"numDirectors": {
"$cond": [{ "$isArray": "$directors" }, { "$size": "$directors" }, 0]
}
},
"numFilms": { "$sum": 1 },
"averageMetacritic": { "$avg": "$metacritic" }
}
},
{
"$sort": { "_id.numDirectors": -1 }
}
])
// showing how to group all documents together. By convention, we use null or an
// empty string, ""
db.movies.aggregate([
{
"$group": {
"_id": null,
"count": { "$sum": 1 }
}
}
])
// filtering results to only get documents with a numeric metacritic value
db.movies.aggregate([
{
"$match": { "metacritic": { "$gte": 0 } }
},
{
"$group": {
"_id": null,
"averageMetacritic": { "$avg": "$metacritic" }
}
}
])
db.movies.count()

Accumulator Stages with $project
// run to get a view of the document schema
db.icecream_data.findOne()
// using $reduce to get the highest temperature
db.icecream_data.aggregate([
{
"$project": {
"_id": 0,
"max_high": {
"$reduce": {
"input": "$trends",
"initialValue": -Infinity,
"in": {
"$cond": [
{ "$gt": ["$$this.avg_high_tmp", "$$value"] },
"$$this.avg_high_tmp",
"$$value"
]
}
}
}
}
}
])
// performing the inverse, grabbing the lowest temperature
db.icecream_data.aggregate([
{
"$project": {
"_id": 0,
"min_low": {
"$reduce": {
"input": "$trends",
"initialValue": Infinity,
"in": {
"$cond": [
{ "$lt": ["$$this.avg_low_tmp", "$$value"] },
"$$this.avg_low_tmp",
"$$value"
]
}
}
}
}
}
])
// note that these two operations can be done with the following operations can
// be done more simply. The following two expressions are functionally identical
db.icecream_data.aggregate([
{ "$project": { "_id": 0, "max_high": { "$max": "$trends.avg_high_tmp" } } }
])
db.icecream_data.aggregate([
{ "$project": { "_id": 0, "min_low": { "$min": "$trends.avg_low_tmp" } } }
])
// getting the average and standard deviations of the consumer price index
db.icecream_data.aggregate([
{
"$project": {
"_id": 0,
"average_cpi": { "$avg": "$trends.icecream_cpi" },
"cpi_deviation": { "$stdDevPop": "$trends.icecream_cpi" }
}
}
])
// using the $sum expression to get total yearly sales
db.icecream_data.aggregate([
{
"$project": {
"_id": 0,
"yearly_sales (millions)": { "$sum": "$trends.icecream_sales_in_millions" }
}
}
])
Lab - $group and Accumulators
db.movies.find({ awards: { $ne: null } },{awards:1 }).pretty()
db.movies.find({ awards: { $ne: null } , year: { $gt: 1995}}, {awards:1, year:1}).pretty()
db.movies.find({ awards: { $ne: null }, awards: {$text: { $search: "Oscar"}} }, {awards:1}).pretty()
db.movies.aggregate([
{
$match: {
awards: /Won \d{1,2} Oscars?/
}
},
{
$group: {
_id: null,
highest_rating: { $max: "$imdb.rating" },
lowest_rating: { $min: "$imdb.rating" },
average_rating: { $avg: "$imdb.rating" },
deviation: { $stdDevSamp: "$imdb.rating" }
}
}
])
The $unwind Stage
Highlights:
$unwindonly works on array values- There are two forms for unwind, short form and long form
- Using unwind on large collections with big documents may lead to performance issues.
Lab - $unwind
Problem:
Let’s use our increasing knowledge of the Aggregation Framework to explore our movies collection in more detail. We’d like to calculate how many movies every cast member has been in and get an average imdb.rating for each cast member.
What is the name, number of movies, and average rating (truncated to one decimal) for the cast member that has been in the most number of movies with English as an available language?
Provide the input in the following order and format
db.movies.aggregate([
{$project: {cast: 1, "rating": "$imdb.rating"}},
{$unwind: "$cast"},
])
I wrote it right!
db.movies.aggregate([
{$match: {languages: {$ne: null}, languages: {"$all": ["English"] }}},
{$project: {cast: 1, languages:1, "rating": "$imdb.rating"}},
{$unwind: "$cast"},
{$group: {"_id": "$cast", "numFilms": {$sum: 1} , "average": {$avg: "$rating"} }},
{$sort: {numFilms: -1}}
])
MongoDB Enterprise Cluster0-shard-0:PRIMARY> db.movies.aggregate([ {$match: {languages: {$ne: null}, languages: {"$all": ["English"] }}}, {$project: {cast: 1, languages:1, "rating": "$imdb.rating"}}, {$unwind: "$cast"}, {$group: {"_id": "$cast", "numFilms": {$sum: 1} , "average": {$avg: "$rating"} }}, {$sort: {numFilms: -1}} ])
{ "_id" : "John Wayne", "numFilms" : 107, "average" : 6.424299065420561 }
{ "_id" : "Michael Caine", "numFilms" : 82, "average" : 6.517073170731707 }
{ "_id" : "Christopher Lee", "numFilms" : 76, "average" : 6.132894736842106 }
{ "_id" : "Robert De Niro", "numFilms" : 75, "average" : 6.690140845070423 }
...
Answer:
db.movies.aggregate([
{
$match: {
languages: "English"
}
},
{
$project: { _id: 0, cast: 1, "imdb.rating": 1 }
},
{
$unwind: "$cast"
},
{
$group: {
_id: "$cast",
numFilms: { $sum: 1 },
average: { $avg: "$imdb.rating" }
}
},
{
$project: {
numFilms: 1,
average: {
$divide: [{ $trunc: { $multiply: ["$average", 10] } }, 10]
}
}
},
{
$sort: { numFilms: -1 }
},
{
$limit: 1
}
])
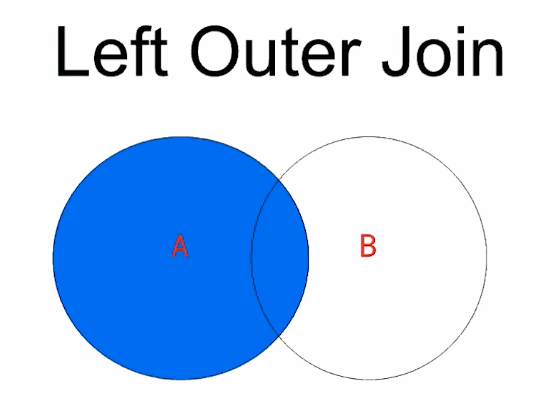
The $lookup State

// familiarizing with the air_alliances schema
db.air_alliances.findOne()
// familiarizing with the air_airlines schema
db.air_airlines.findOne()
// performing a lookup, joining air_alliances with air_airlines and replacing
// the current airlines information with the new values
db.air_alliances.aggregate([
{
"$lookup": {
"from": "air_airlines",
"localField": "airlines",
"foreignField": "name",
"as": "airlines"
}
}
]).pretty()
- The from collection cannot be sharded
- The from collection must be in the same database
- The values in localField and foreignField are matched on equality
- as can be any name, but if it exists in the working document that field will be overwritten
Lab - Using $lookup
Problem:
Which alliance from air_alliances flies the most routes with either a Boeing 747 or an Airbus A380 (abbreviated 747 and 380 in air_routes)?
db.air_routes.aggregate([
{
$match: {
airplane: /747|380/
}
},
{
$lookup: {
from: "air_alliances",
foreignField: "airlines",
localField: "airline.name",
as: "alliance"
}
},
{
$unwind: "$alliance"
},
{
$group: {
_id: "$alliance.name",
count: { $sum: 1 }
}
},
{
$sort: { count: -1 }
}
])
We begin by aggregating over our air_routes collection to allow for filtering of documents containing the string “747” or “380”. If we started from air_alliances we would have to do this after the lookup!
Next, we use the $lookup stage to match documents from air_alliances on the value of their airlines field against the current document’s airline.name field
We then use $unwind on the alliance field we created in $lookup, creating a document with each entry in alliance
We end with a $group and $sort stage, grouping on the name of the alliance and counting how many times it appeared
$graphLookup Introduction
Operational + Analytical
Which of the following statements apply to $graphLookup operator? check all that apply
- $graphLookup provides MongoDB a transitive closure implementation
- Provides MongoDB with graph or graph-like capabilities
$graphLookup: Simple Lookup
db.parent_reference.find()
db.parent_reference.find({name: "Dev"})
db.parent_reference.find({"reports_to": 1})
db.parent_reference.find({"reports_to": 2})
find the descendants/subordinates
db.parent_reference.aggregate(
[
{$match: {name: "Eliot"}},
{$graphLookup: {
from: "parent_reference",
startWith: "$_id",
connectFromField: "_id",
connectToField: "reports_to",
as: "all_reports"
}}
]
)
Find the boss
db.parent_reference.aggregate(
[
{$match: {name: "Eliot"}},
{$graphLookup: {
from: "parent_reference",
startWith: "$reports_to",
connectFromField: "reports_to",
connectToField: "_id",
as: "bosses"
}}
]
)
connectToField will be used on recursive find operations.
connectFromField value will be use to match connectToField in a recursive match
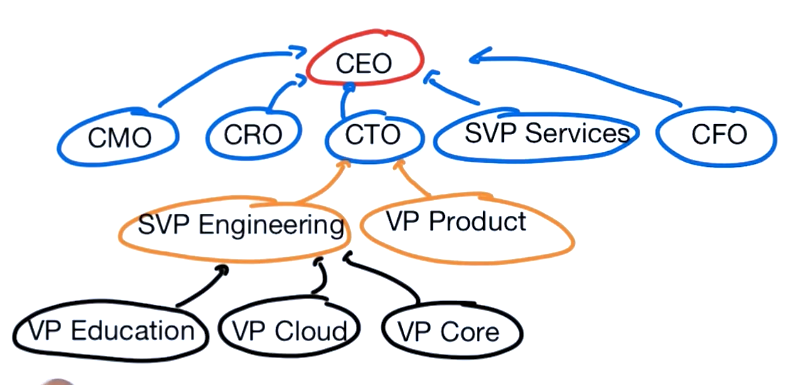
$graphLookup: Simple Lookup Reverse Schema
db.child_reference.findOne({name: "Dev"})
db.child_reference.aggregate([
{$match:{name: "Dev"}},
{
$graphLookup:{
from: "child_reference",
startWith: "$direct_reports",
connectFromField: "direct_reports",
connectToField: "name",
as: "all_reports"
}
}
]).pretty()
// results:
{
"_id" : 1,
"name" : "Dev",
"title" : "CEO",
"direct_reports" : [
"Eliot",
"Meagen",
"Carlos",
"Richard",
"Kristen"
],
"all_reports" : [
{
"_id" : 11,
"name" : "Cailin",
"title" : "VP Cloud Engineering"
},
{
"_id" : 5,
"name" : "Andrew",
"title" : "VP Eng",
"direct_reports" : [
"Cailin",
"Dan",
"Shannon"
]
},
{
"_id" : 7,
"name" : "Elyse",
"title" : "COO"
},
{
"_id" : 10,
"name" : "Dan",
"title" : "VP Core Engineering"
},
{
"_id" : 8,
"name" : "Richard",
"title" : "VP PS"
},
{
"_id" : 9,
"name" : "Shannon",
"title" : "VP Education"
},
{
"_id" : 4,
"name" : "Carlos",
"title" : "CRO"
},
{
"_id" : 3,
"name" : "Meagen",
"title" : "CMO"
},
{
"_id" : 6,
"name" : "Ron",
"title" : "VP PM"
},
{
"_id" : 2,
"name" : "Eliot",
"title" : "CTO",
"direct_reports" : [
"Andrew",
"Elyse",
"Ron"
]
}
]
}
$graphLookup: maxDepth and depthField
db.child_reference.aggregate([
{$match:{name: "Dev"}},
{
$graphLookup:{
from: "child_reference",
startWith: "$direct_reports",
connectFromField: "direct_reports",
connectToField: "name",
as: "till_2_level_reports",
maxDepth: 1
}
}
]).pretty()
db.child_reference.aggregate([
{$match:{name: "Dev"}},
{
$graphLookup:{
from: "child_reference",
startWith: "$direct_reports",
connectFromField: "direct_reports",
connectToField: "name",
as: "till_2_level_reports",
maxDepth: 1,
//how many levels are needed
depthField: 'level'
}
}
]).pretty()
- maxDepth allows you to specify the number of recursive lookups
- depthField determines a field in the result document, which specifies the number of recursive lookups needed to reach that document
$graphLookup: Cross Collection Lookup
db.air_airlines.aggregate([
{$match:{name: "TAP Portugal"}},
{
$graphLookup:{
from: "routes",
startWith: "$base",
connectFromField: "dst_airport",
connectToField: "src_airport",
as: "chain",
maxDepth: 1,
restrictSearchWithMatch:{"airline.name": "TAP Portugal"}
}
}
]).pretty()
$graphLookup: General Considerations
- Memory allocation: $allowDiskUse
- Indexes: connectToField
- from collection can not be Sharded
- $match
$graphLookup can be used in any position of the pipeline and acts in the same way as a regular $lookup.
Lab: $graphLookup (Hard Problem)
db.air_alliances.aggregate([
{
$match: { name: "OneWorld" }
},
{
$graphLookup: {
startWith: "$airlines",
from: "air_airlines",
connectFromField: "name",
connectToField: "name",
as: "airlines",
maxDepth: 0,
restrictSearchWithMatch: {
country: { $in: ["Germany", "Spain", "Canada"] }
}
}
},
{
$graphLookup: {
startWith: "$airlines.base",
from: "air_routes",
connectFromField: "dst_airport",
connectToField: "src_airport",
as: "connections",
maxDepth: 1
}
},
{
$project: {
validAirlines: "$airlines.name",
"connections.dst_airport": 1,
"connections.airline.name": 1
}
},
{ $unwind: "$connections" },
{
$project: {
isValid: {
$in: ["$connections.airline.name", "$validAirlines"]
},
"connections.dst_airport": 1
}
},
{ $match: { isValid: true } },
{
$group: {
_id: "$connections.dst_airport"
}
}
])