Introduction to Patterns
Patterns(设计模式) are for data modeling and schema design.
- Use computed pattern to avoid repetitive computations
- Structure similar fields with the attribute pattern
- Handle changes to your deployment with no downtime with a schema versioning pattern
Guide to Homework Validation
To help verify the syntax of your JSON files
To learn more about JSON Schema
JSON Schema validation reference.
Handling Duplication, Staleness and Integrity
Handling Duplication
Duplication may cause inconsistancy when you change one piece of data while the duplication part not changed. This should be maintained by the application.
Duplication Examples
- A clinet’s address should be fixed and embeded in one order.
- A movie’s cast should be the names of actors, should be fixd and embeded.
Handling Staleness
Staleness means out-of-date data.
Handling Referential Integrity
Linking information between documents and tables.
No support for cascading deletes.
Challenge for correctness and consistency.
Which of the following are valid concerns regarding duplication, staleness and referential integrity management in a MongoDB database and appropriate resolution techniques?
- Data integrity issues can be minimized by using multi-document transactions.
- Data staleness issues can be minimized with frequent batch updates.
Attribute Pattern




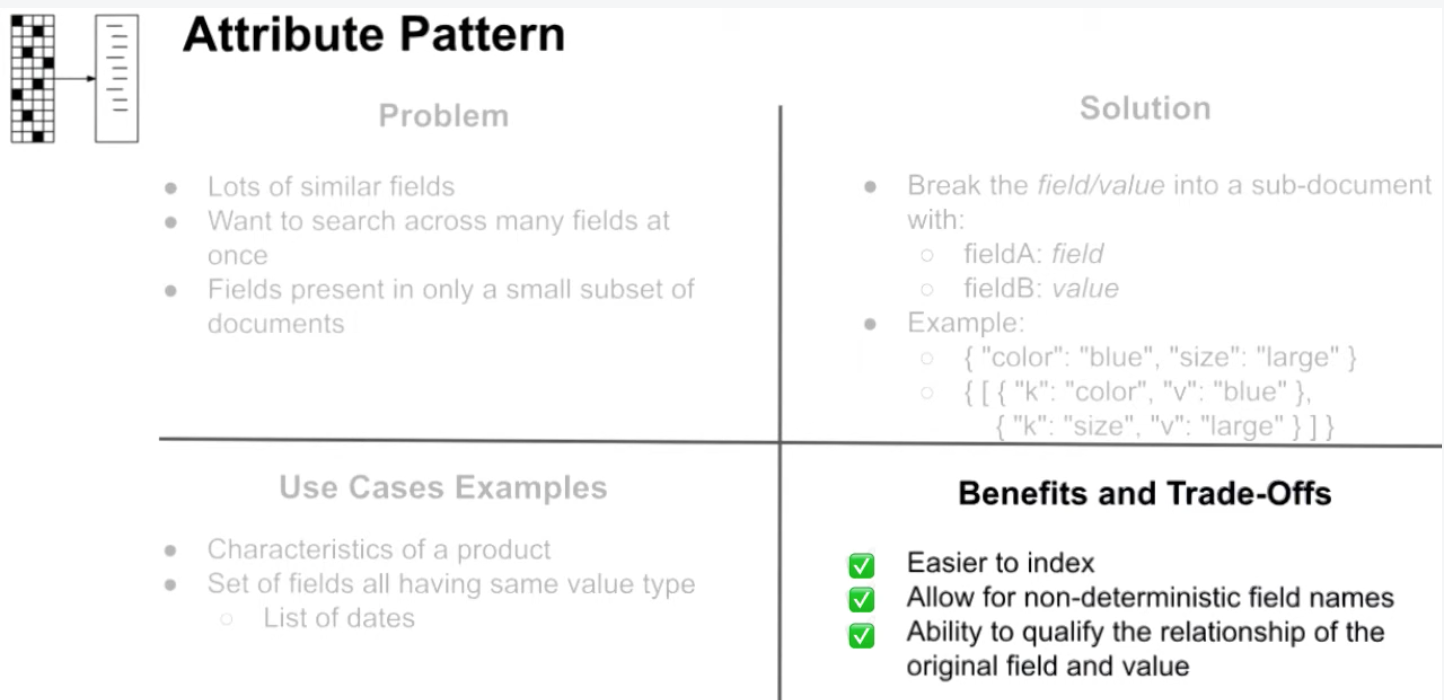

Which one of the following scenarios is best suited for the application of the Attribute Pattern? Some fields share a number of characteristics, and we want to search across those fields.
Lab
From
{
"_id": "<objectId>",
"title": "<string>",
"artist": "<string>",
"date_acquisition": "<date>",
"location": "<string>",
"on_display": "<bool>",
"in_house": "<bool>",
"events": [{
"moma": "<date>",
"louvres": "<date>"
}]
}
to
{
"_id": "<objectId>",
"title": "<string>",
"location": "<string>",
"artist": "<string>",
"on_display": "<bool>",
"in_house": "<bool>",
"events": [
{"k": "<string>", "v": "<date>"},
{"k": "<string>", "v": "<date>"}
]
}
Extended Reference Pattern
How joins are performed in MongoDB
- Application side
- Lookups
$lookupgraphLookup
- Avod a join by embedding the joined table!
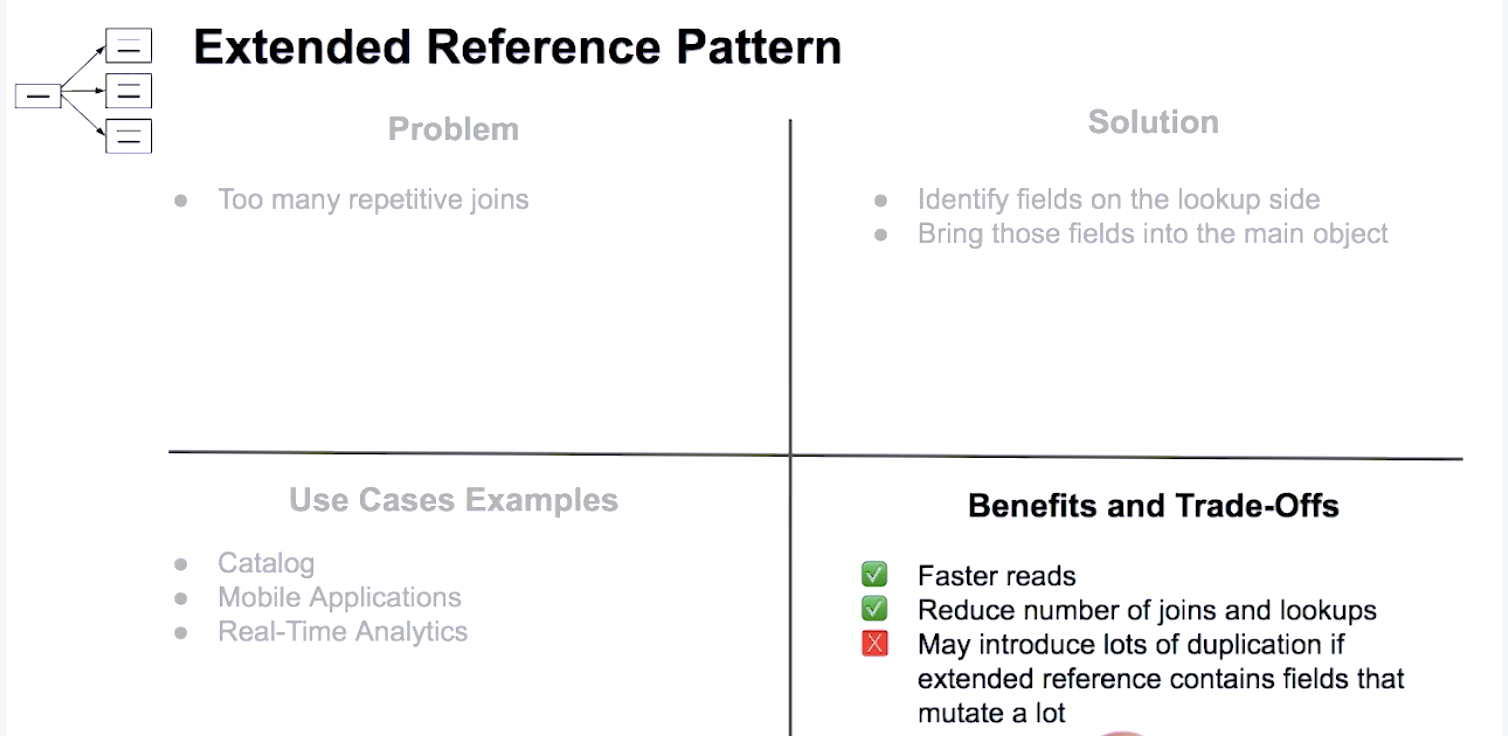
Which one of the following scenarios is the best candidate to use the Extended Reference Pattern to avoid doing additional reads through joins/lookups? An app needs to retrieve a product and information about its supplier.
This is a good scenario for the Extended Reference Pattern. It is likely that we want to carry some information about a supplier with the product, however not all of it. Having fields like the supplier’s name, a reference number, and the supplier’s phone number should provide all the information we need when looking at a product. Additional information like the complete address and billing contact should be left within the suppliers collection.
Subset Pattern
Working set is too big:
- add RAM
- Scale with Sharding
- reduce the size of the set
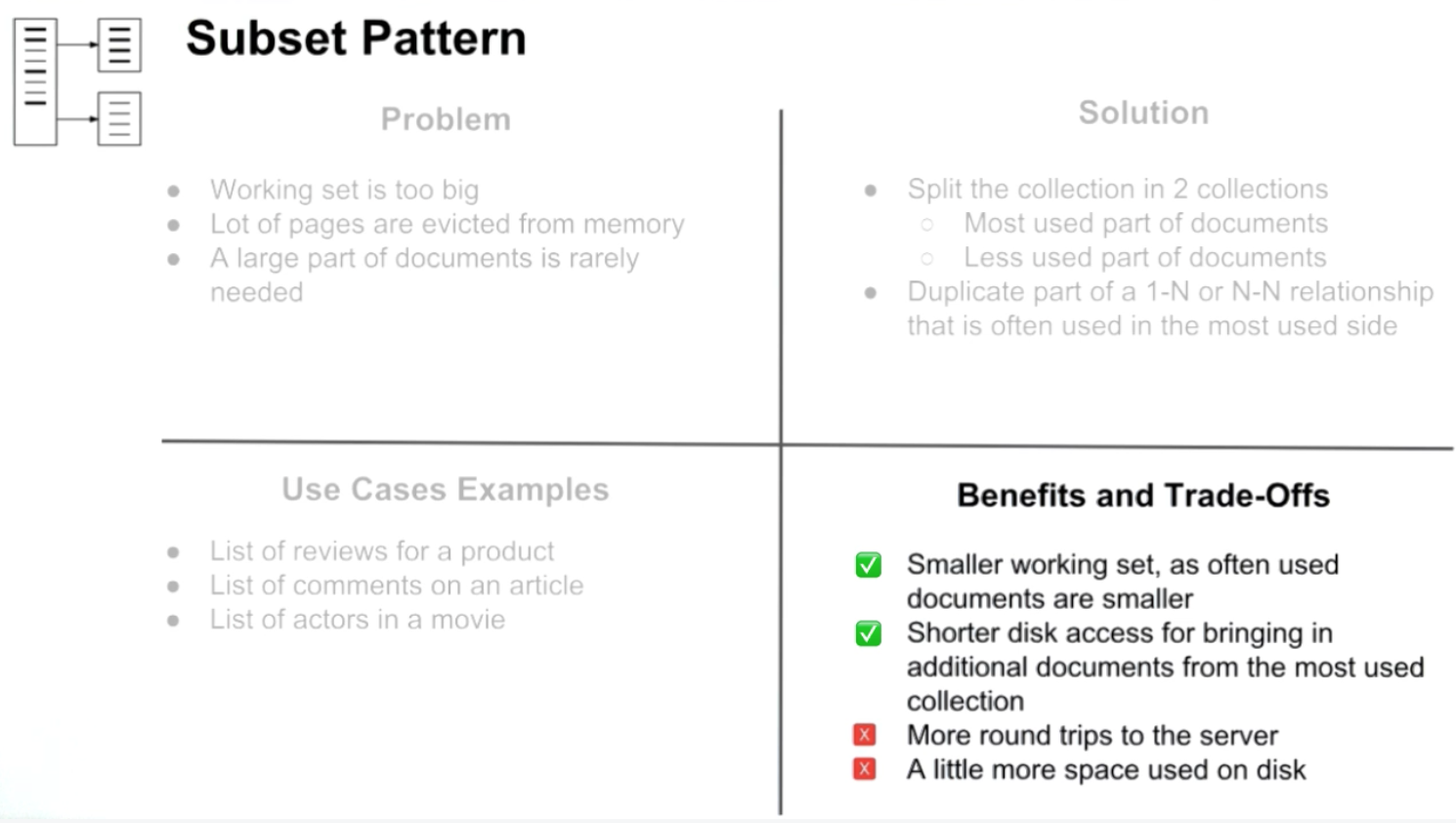
Which one of the following scenarios is the best candidate for use of the Subset Pattern? The working set does not fit in memory and it is difficult to scale the hardware.
Comments