Introduction to Indexes
- What are indexes?
- How do they work?
What problem do indexes try to solve?
Slow queries
Think about a book index.
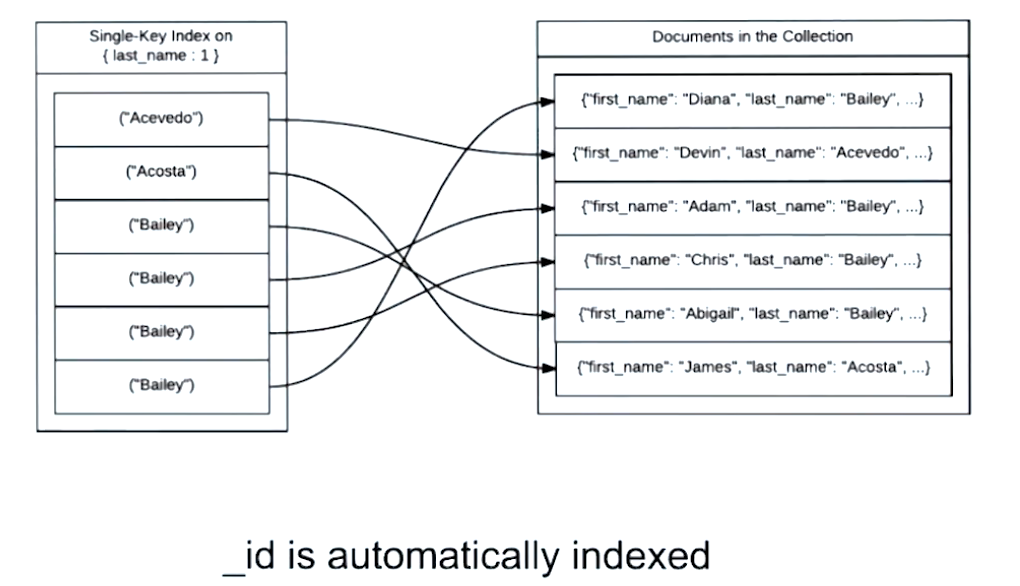
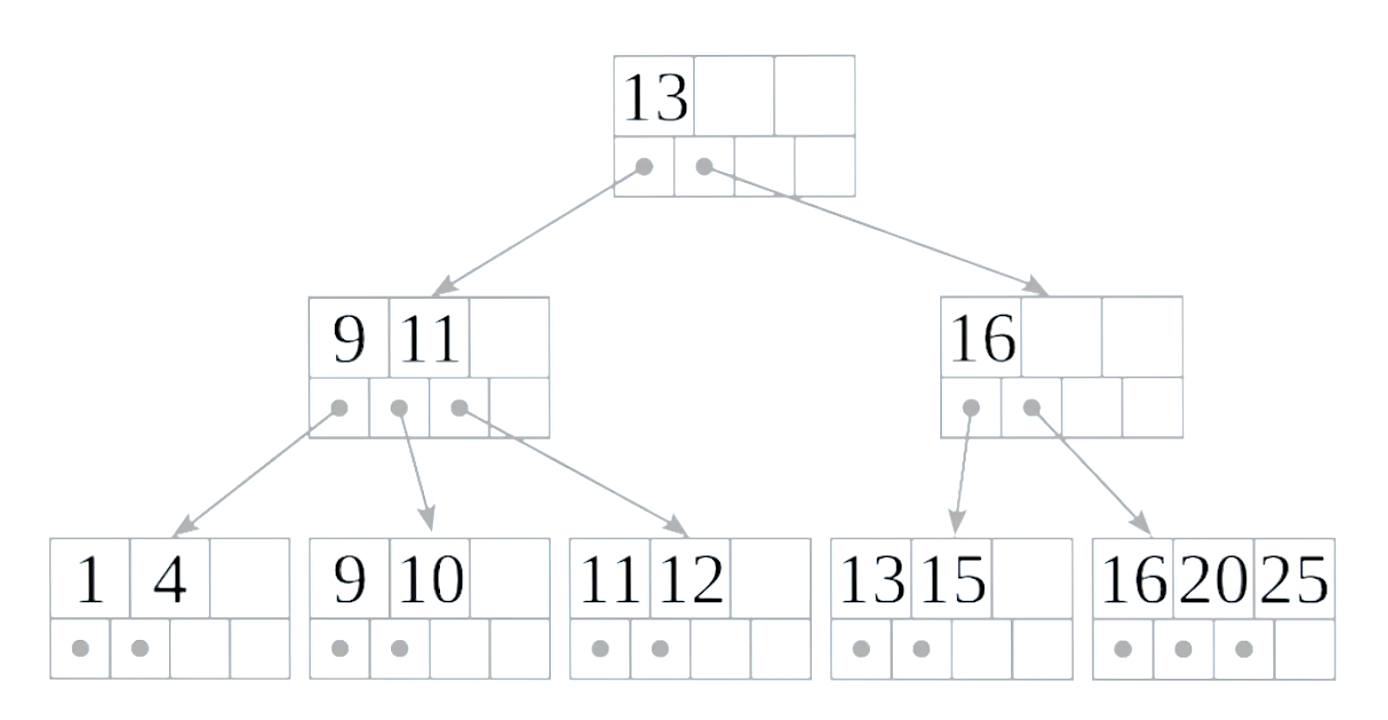
B-tree
Index Overhead
- Indexes are used to increase the speed of our queries.
- The _id field is automatically indexed on all collections.
- Indexes reduce the number of documents MongoDB needs to examine to satisfy a query.
- Indexes can decrease write, update, and delete performance.
How Data is Stored on Disk
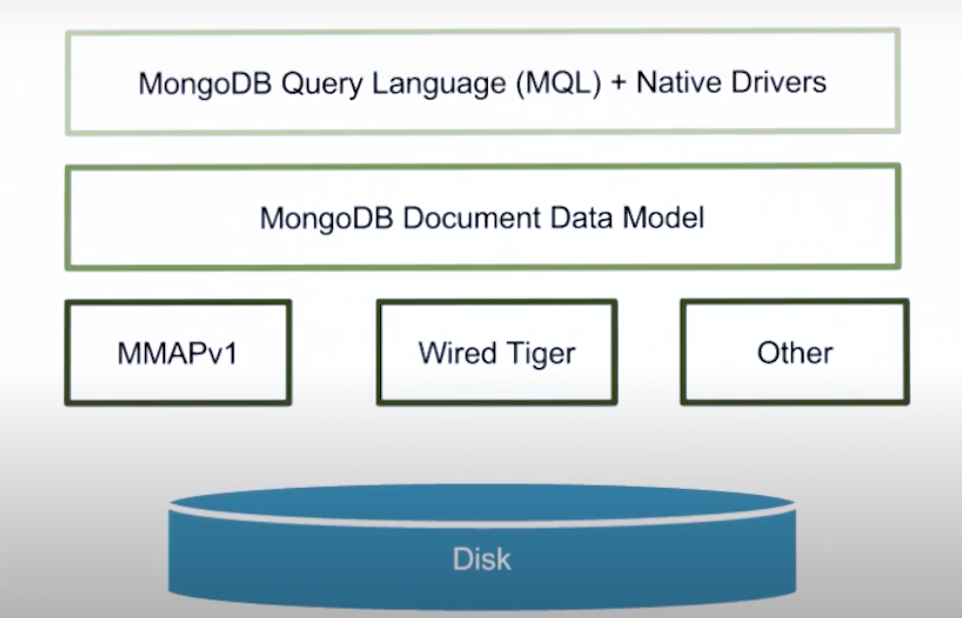
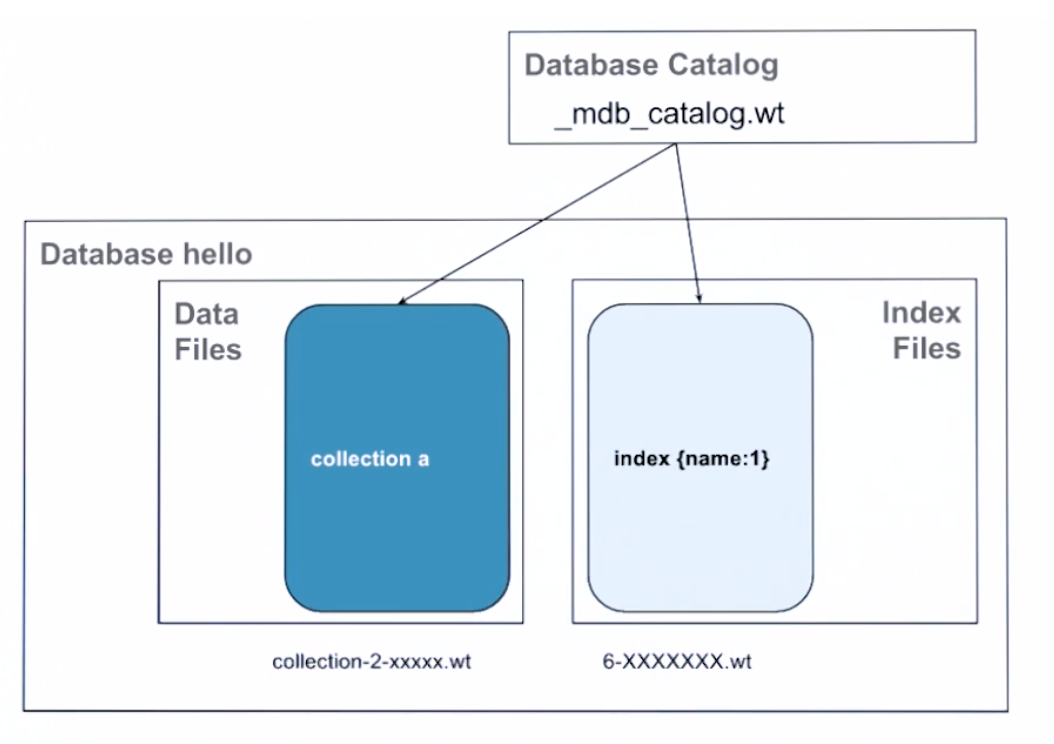
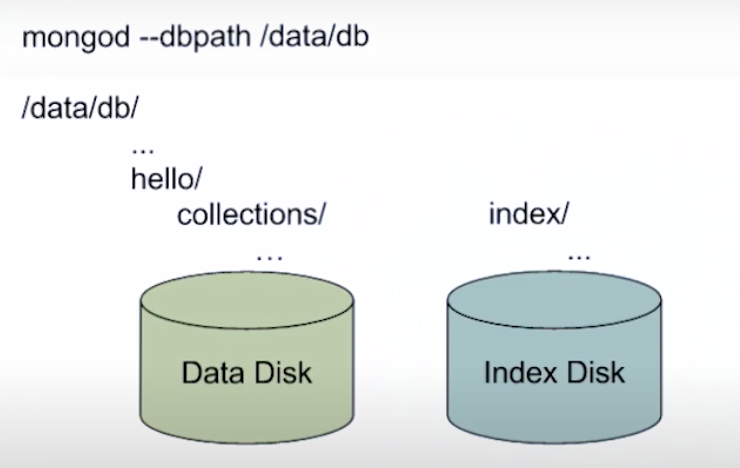
Using compression while store information to disk.
db.collection.insert({}, {writeConcern: {w:3}})
The journal file acts as a safeguard against data corruption caused by incomplete data file writes.
Single Field Indexes Part 1
- Simplest indexes in MongoDB
db.collection.createIndex({<field>: <direction>})- key features
- keys from only one field
- can find a single value for the indexed field
- can find a range of values
- cat use dot notation to index fields in subdocuments
- can be used to find several distinct values in a single query
// execute the following query and collect execution statistics
db.people.find({ "ssn" : "720-38-5636" }).explain("executionStats")
// stage: COLLSCAN
// create an ascending index on ssn
db.people.createIndex( { ssn : 1 } )
// create an explainable object for the people collection
exp = db.people.explain("executionStats")
// execute the same query again (should use an index)
exp.find( { "ssn" : "720-38-5636" } )
// execute a new query on the explainable object (can't use the index)
exp.find( { last_name : "Acevedo" } )
// "stage": "IXSCAN"
// insert a documents with an embedded document
db.examples.insertOne( { _id : 0, subdoc : { indexedField: "value", otherField : "value" } } )
db.examples.insertOne( { _id : 1, subdoc : { indexedField : "wrongValue", otherField : "value" } } )
// create an index using dot-notation
db.examples.createIndex( { "subdoc.indexedField" : 1 } )
// explain a query using dot-notation
db.examples.explain("executionStats").find( { "subdoc.indexedField" : "value" } )
Single Field Indexes Part 2
// explain a range query (using an index)
exp.find( { ssn : { $gte : "555-00-0000", $lt : "556-00-0000" } } )
// explain a query on a set of values
exp.find( { "ssn" : { $in : [ "001-29-9184", "177-45-0950", "265-67-9973" ] } } )
// explain a query where only part of the predicates use a index
exp.find( { "ssn" : { $in : [ "001-29-9184", "177-45-0950", "265-67-9973" ] }, last_name : { $gte : "H" } } )
Understanding Explain

// switch to the m201 database
use m201
// create an explainable object with no parameters
// does not excute the quries
exp = db.people.explain()
// create an explainable object with the 'executionStats' parameter
// excute the quries
expRun = db.people.explain("executionStats")
// and one final explainable object with the 'allPlansExecution' parameter
// excute the quries
expRunVerbose = db.people.explain("allPlansExecution")
// execute and explain the query, collecting execution statistics
expRun.find({"last_name":"Johnson", "address.state":"New York"})
// create an index on last_name
db.people.createIndex({last_name:1})
// rerun the query (uses the index)
expRun.find({"last_name":"Johnson", "address.state":"New York"})
// create a compound index
db.people.createIndex({"address.state": 1, last_name: 1})
// rerun the query (uses the new index)
expRun.find({"last_name":"Johnson", "address.state":"New York"})
// run a sort query
var res = db.people.find({"last_name":"Johnson", "address.state":"New York"}).sort({"birthday":1}).explain("executionStats")
// checkout the execution stages (doing an in-memory sort)
res.executionStats.executionStages
The “stage” : “SORT” tells us the index was not use for the sort and a sort had to done, so it had to be done in memory.
Problem
If you observe the following lines in the output of explain(’executionStats’), what can you deduce?
"executionStats" : {
"executionSuccess" : true,
"nReturned" : 23217,
"executionTimeMillis" : 91,
"totalKeysExamined" : 23217,
"totalDocsExamined" : 23217,
"executionStages" : {
"stage" : "SORT",
"nReturned" : 23217,
"executionTimeMillisEstimate" : 26,
"works" : 46437,
"advanced" : 23217,
"needTime" : 23219,
"needYield" : 0,
"saveState" : 363,
"restoreState" : 363,
"isEOF" : 1,
"sortPattern" : {
"stars" : 1
},
"memUsage" : 32522511,
"memLimit" : 33554432,
- The index selected for the query was not useful for the sort part of the query
- An in-memory sort was performed
- The system came very close to throwing an exception instead of returning results
Understanding Explain for Sharded Clusters
#!/usr/bin/env bash
# use mlaunch from mtools to startup a sharded cluster
mlaunch init --single --sharded 2
# after sharding the collection, import some documents
mongoimport -d m201 -c people people.json
// switch to the m201 database
use m201
// enable sharding on the m201 database
sh.enableSharding("m201")
// shard the people collection on the _id index
sh.shardCollection("m201.people", {_id: 1})
// after the import, check the shard distribution (data should be on both shards)
db.people.getShardDistribution()
// checkout the explain output for a sharded collection
db.people.find({"last_name":"Johnson", "address.state":"New York"}).explain("executionStats")
- Execution time
- Number of keys read, documents read documents returned
- Plans selected and rejected
Sorting with Indexes
- sort in memory
- sort by using an index
Sorting memory limit is 32MB.
#!/usr/bin/env bash
# import the people dataset if you haven't already
mongoimport -d m201 -c people --drop people.json
# connect to the server
mongo
// switch to the m201 database
use m201
// find all documents and sort them by ssn
db.people.find({}, { _id : 0, last_name: 1, first_name: 1, ssn: 1 }).sort({ ssn: 1 })
// create an explainable object for the people collection
var exp = db.people.explain('executionStats')
// and rerun the query (uses the index for sorting)
exp.find({}, { _id : 0, last_name: 1, first_name: 1, ssn: 1 }).sort({ ssn: 1 })
// this time, sort by first_name (didn't use the index for sorting)
exp.find({}, { _id : 0, last_name: 1, first_name: 1, ssn: 1 }).sort({ first_name: 1 })
// and rerun the first query, but sort descending (walks the index backward)
exp.find({}, { _id : 0, last_name: 1, first_name: 1, ssn: 1 }).sort({ ssn: -1 })
// filtering and sorting in the same query (both using the index, backward)
exp.find( { ssn : /^555/ }, { _id : 0, last_name: 1, first_name: 1, ssn: 1 } ).sort( { ssn : -1 } )
// drop all indexes
db.people.dropIndexes()
// create a new descending (instead of ascending) index on ssn
db.people.createIndex({ ssn: -1 })
// rerun the same query, now walking the index forward
exp.find( { ssn : /^555/ }, { _id : 0, last_name: 1, first_name: 1, ssn: 1 } ).sort( { ssn : -1 } )
Problem
Given the following schema for the products collection:
{
"_id": ObjectId,
"product_name": String,
"product_id": String
}
And the following index on the products collection:
{ product_id: 1 }
Which of the following queries will use the given index to perform the sorting of the returned documents?
db.products.find({}).sort({ product_id: 1 })
// Yes.
db.products.find({}).sort({ product_id: -1 })
// Yes, in this case the index will be traversed backwards for sorting.
db.products.find({ product_id: '57d7a1' }).sort({ product_id: -1 })
// Yes, in this case the index will be used to filter and sort by traversing the index backwards.
db.products.find({ product_name: 'Soap' }).sort({ product_id: 1 })
// Yes, in this case the index will be used to first fetch the sorted documents, and then the server will filter on products that match the product name.
Querying on Compound Indexes Part 1
A compound index is an index on two or more fields.
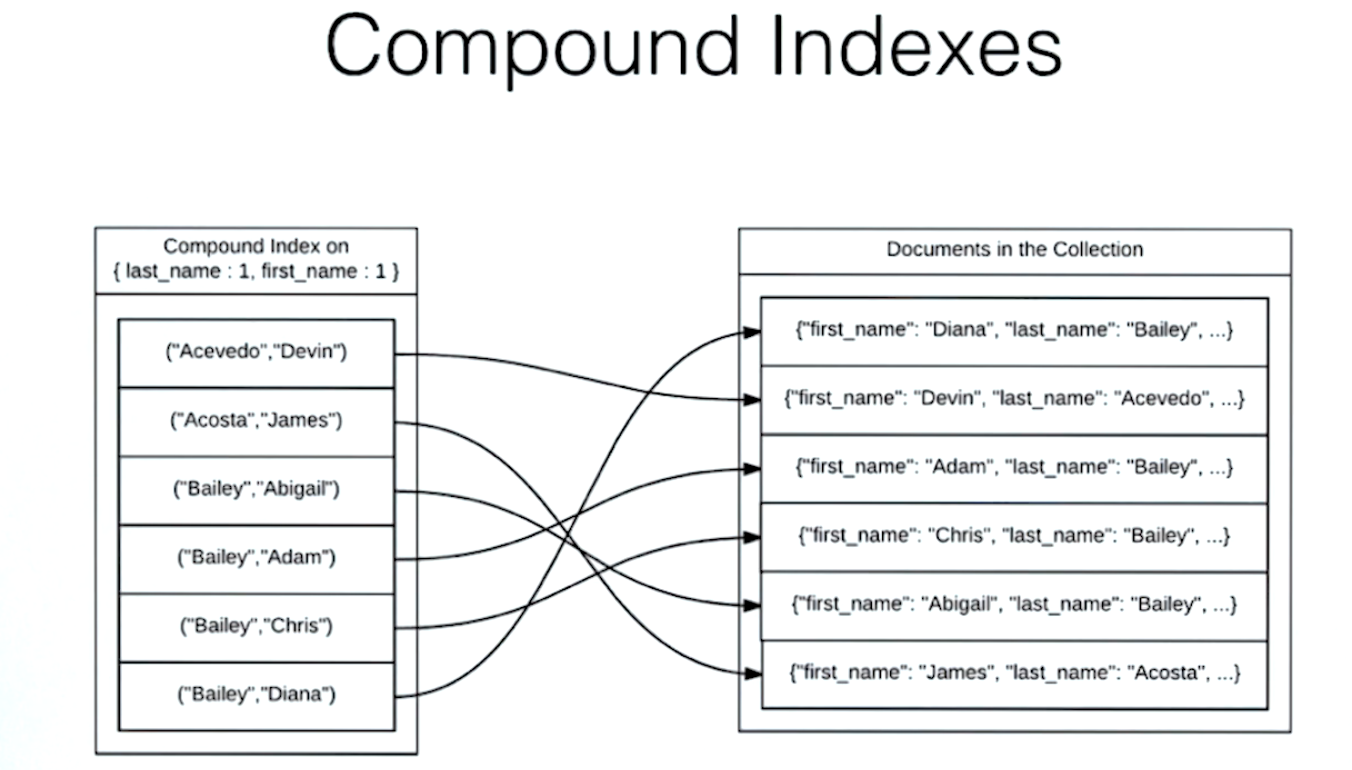
The order matters.
A, A -> doc3
A, B -> doc2
A, C -> doc6
B, A ...
B, B
Querying on Compound Indexes Part 2
Index Prefixes
{"item": 1, "location": 1, "stock": 1 }
If your query is
{"last_name": "jack", "first_name": "tom", }
you should create an index like this:
{"last_name":1, "first_name": 1, }
When you can sort with Indexes
Indexes have orders, the order matters.
- Index prefixes can be used in query predicates to increase index utilization.
- Index prefixes can be used in sort predicates to prevent in-memory sorts.
- We can invert the keys of an index in our sort predicate to utilize an index by walking it backwards.
// confirm you still have an index on job, employer, last_name, & first_name
db.people.getIndexes()
// create an explainable object for the people collection
var exp = db.people.explain("executionStats")
// sort all documents using the verbatim index key pattern
exp.find({}).sort({ job: 1, employer: 1, last_name : 1, first_name : 1 })
// sort all documents using the first two fields of the index (uses the index)
exp.find({}).sort({ job: 1, employer: 1 })
// sort all documents, swapping employer and job (doesn't use the index)
exp.find({}).sort({ employer: 1, job: 1 })
// all of these queries can use the index
db.people.find({}).sort({ job: 1 })
db.people.find({}).sort({ job: 1, employer: 1 })
db.people.find({}).sort({ job: 1, employer: 1, last_name: 1 })
// will still use the index (for sorting)
exp.find({ email:"jenniferfreeman@hotmail.com" }).sort({ job: 1 })
// use the index for filtering and sorting
exp.find({ job: 'Graphic designer', employer: 'Wilson Ltd' }).sort({ last_name: 1 })
// doesn't follow an index prefix, and can't use the index for sorting, only filtering
exp.find({ job: 'Graphic designer' }).sort({ last_name: 1 })
// create a new compound index
db.coll.createIndex({ a: 1, b: -1, c: 1 })
// walk the index forward
db.coll.find().sort({ a: 1, b: -1, c: 1 })
// walk the index backward, by inverting the sort predicate
db.coll.find().sort({ a: -1, b: 1, c: -1 })
// all of these queries use the index for sorting
// forwards
db.coll.find().sort({ a: 1 })
db.coll.find().sort({ a: 1, b: -1 })
// backwards
db.coll.find().sort({ a: -1 })
db.coll.find().sort({ a: -1, b: 1 })
// uses the index for sorting
exp.find().sort({job: -1, employer: -1})
// sorting is done in-memory
exp.find().sort({job: -1, employer: 1})
In order to use the compound index, the sort field order must be same as the order of index.
Multikey Indexes
// switch to the m201 database
use m201
// insert a document into the products collection
db.products.insert({
productName: "MongoDB Short Sleeve T-Shirt",
categories: ["T-Shirts", "Clothing", "Apparel"],
stock: { size: "L", color: "green", quantity: 100 }
});
// create an index on stock.quantity
db.products.createIndex({ "stock.quantity": 1})
// create an explainable object on the products collection
var exp = db.products.explain()
// look at the explain output for the query (uses an index, isMultiKey is false)
exp.find({ "stock.quantity": 100 })
// insert a document where stock is now an array
db.products.insert({
productName: "MongoDB Long Sleeve T-Shirt",
categories: ["T-Shirts", "Clothing", "Apparel"],
stock: [
{ size: "S", color: "red", quantity: 25 },
{ size: "S", color: "blue", quantity: 10 },
{ size: "M", color: "blue", quantity: 50 }
]
});
// rerun our same query (still uses an index, but isMultiKey is now true)
exp.find({ "stock.quantity": 100 })
// creating an index on two array fields will fail
db.products.createIndex({ categories: 1, "stock.quantity": 1 })
// but compound indexes with only 1 array field are good
db.products.createIndex({ productName: 1, "stock.quantity": 1 })
// productName can be an array if stock isn't
db.products.insert({
productName: [
"MongoDB Short Sleeve T-Shirt",
"MongoDB Short Sleeve Shirt"
],
categories: ["T-Shirts", "Clothing", "Apparel"],
stock: { size: "L", color: "green", quantity: 100 }
});
// but this will fail, because both productName and stock are arrays
db.products.insert({
productName: [
"MongoDB Short Sleeve T-Shirt",
"MongoDB Short Sleeve Shirt"
],
categories: ["T-Shirts", "Clothing", "Apparel"],
stock: [
{ size: "S", color: "red", quantity: 25 },
{ size: "S", color: "blue", quantity: 10 },
{ size: "M", color: "blue", quantity: 50 }
]
});
Problem
Given the following index:
{ name: 1, emails: 1 }
When the following document is inserted, how many index entries will be created?
{
"name": "Beatrice McBride",
"age": 26,
"emails": [
"puovvid@wamaw.kp",
"todujufo@zoehed.mh",
"fakmir@cebfirvot.pm"
]
}
Three is the correct answer. There would be the following index entries:
"Beatrice McBride", "puovvid@wamaw.kp"
"Beatrice McBride", "todujufo@zoehed.mh"
"Beatrice McBride", "fakmir@cebfirvot.pm"
Partial Indexes
Sometimes, it makes sense for us to only index a portion of the documents in a collection.
// switch to the m201 database
use m201
// insert a restaurant document
db.restaurants.insert({
"name" : "Han Dynasty",
"cuisine" : "Sichuan",
"stars" : 4.4,
"address" : {
"street" : "90 3rd Ave",
"city" : "New York",
"state" : "NY",
"zipcode" : "10003"
}
});
// and run a find query on city and cuisine
db.restaurants.find({'address.city': 'New York', 'cuisine': 'Sichuan'})
// create an explainable object
var exp = db.restaurants.explain()
// and rerun the query
exp.find({'address.city': 'New York', cuisine: 'Sichuan'})
// create a partial index
db.restaurants.createIndex(
{ "address.city": 1, cuisine: 1 },
{ partialFilterExpression: { 'stars': { $gte: 3.5 } } }
)
// rerun the query (doesn't use the partial index)
db.restaurants.find({'address.city': 'New York', 'cuisine': 'Sichuan'})
// adding the stars predicate allows us to use the partial index
exp.find({'address.city': 'New York', cuisine: 'Sichuan', stars: { $gt: 4.0 }})

- You cannot specify both the partialFilterExpression and the sparse options
- _id indexes cannot be partial indexes
- shard key indexes cannot be partial indexes
Problem
- Partial indexes represent a superset of the functionality of sparse indexes.
- Partial indexes can be used to reduce the number of keys in an index.
- Partial indexes support compound indexes.
Text Indexes
// switch to the m201 database
use m201
// insert 2 example documents
db.textExample.insertOne({ "statement": "MongoDB is the best" })
db.textExample.insertOne({ "statement": "MongoDB is the worst." })
// create a text index on "statement"
db.textExample.createIndex({ statement: "text" })
// Search for the phrase "MongoDB best"
db.textExample.find({ $text: { $search: "MongoDB best" } })
// Display each document with it's "textScore"
db.textExample.find({ $text: { $search : "MongoDB best" } }, { score: { $meta: "textScore" } })
// Sort the documents by their textScore so that the most relevant documents
// return first
db.textExample.find({ $text: { $search : "MongoDB best" } }, { score: { $meta: "textScore" } }).sort({ score: { $meta: "textScore" } })
Limit the index size to one category(Important)

Which other type of index is mostly closely related to text indexes?
Multi-key indexes
Yes, both multi-key and text indexes can potentially create many more index keys for each document in the collection.
Chinese is not supported.
Collations(校对)
Collation allows users to specify language-specific rules for string comparison, such as rules for lettercase and accent marks.
You can specify collation for a collection or a view, an index, or specific operations that support collation.
{
locale: <string>,
caseLevel: <boolean>,
caseFirst: <string>,
strength: <int>,
numericOrdering: <boolean>,
alternate: <string>,
maxVariable: <string>,
backwards: <boolean>
}
Wildcard Index Type
Using the wildcardProjection flag with Wildcard Indexes, we can:
- exclude a set of fields from the Wildcard Index.
- include a set of fields in the Wildcard Index.
Wildcard Index Use Cases
- Unpredictable query shapes
- Attribute pattern

Which of the following are good reasons to use a Wildcard Index?
- The query pattern on documents of a collection is unpredictable.
- An application consistently queries against document fields that use the Attribute Pattern.
Lab 2.1: Using Indexes to Sort
In this lab you’re going to determine which queries are able to successfully use a given index for both filtering and sorting.
Given the following index:
{ "first_name": 1, "address.state": -1, "address.city": -1, "ssn": 1 }
Which of the following queries are able to use it for both filtering and sorting?
db.people.find({ "first_name": "Jessica" }).sort({ "address.state": 1, "address.city": 1 })
db.people.find({ "first_name": "Jessica", "address.state": { $lt: "S"} }).sort({ "address.state": 1 })
db.people.find({ "address.state": "South Dakota", "first_name": "Jessica" }).sort({ "address.city": -1 })
Lab 2.2: Optimizing Compound Indexes
In this lab you’re going to examine several example queries and determine which compound index will best service them.
> db.people.find({
"address.state": "Nebraska",
"last_name": /^G/,
"job": "Police officer"
})
> db.people.find({
"job": /^P/,
"first_name": /^C/,
"address.state": "Indiana"
}).sort({ "last_name": 1 })
> db.people.find({
"address.state": "Connecticut",
"birthday": {
"$gte": ISODate("2010-01-01T00:00:00.000Z"),
"$lt": ISODate("2011-01-01T00:00:00.000Z")
}
})
{ "address.state": 1, "last_name": 1, "job": 1 }
Yes, this is the best index. This index matches the first query, can be used for sorting on the second, and has an prefix for the 3rd query.