Performance Considerations in Distributed Systems Part 1
- Replica Cluster(HA Solution)
- Shard Cluster(Horizontal Scalability)
Working with Distributed Systems
- Consider latency
- Data is spread across different nodes
- Read implications
- Write implications
Having a replica set is super important.
Topology of a cluster

Before Sharding
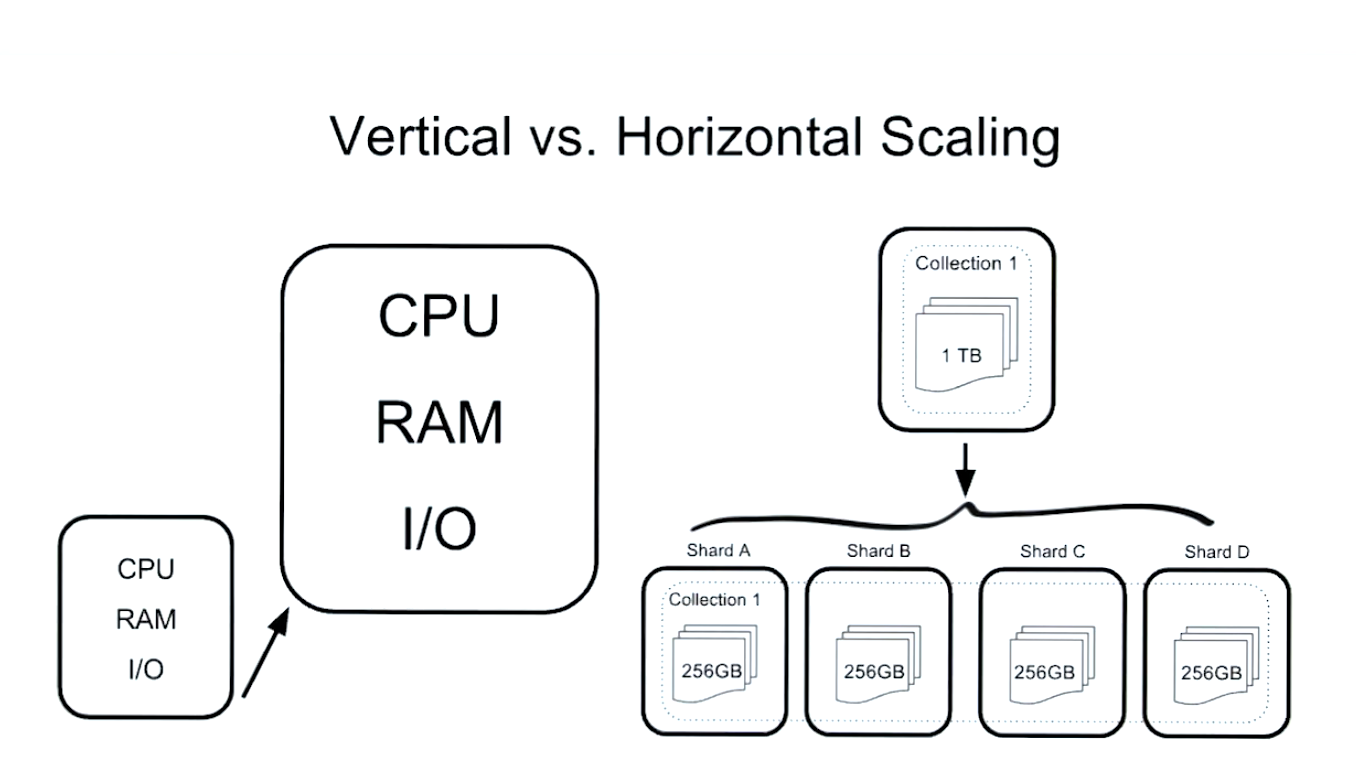
- Sharding is an horizontal scaling solution
- Have we reached the limits of our vertical scaling?
- You need to understand how your data grows and how your data is accessed
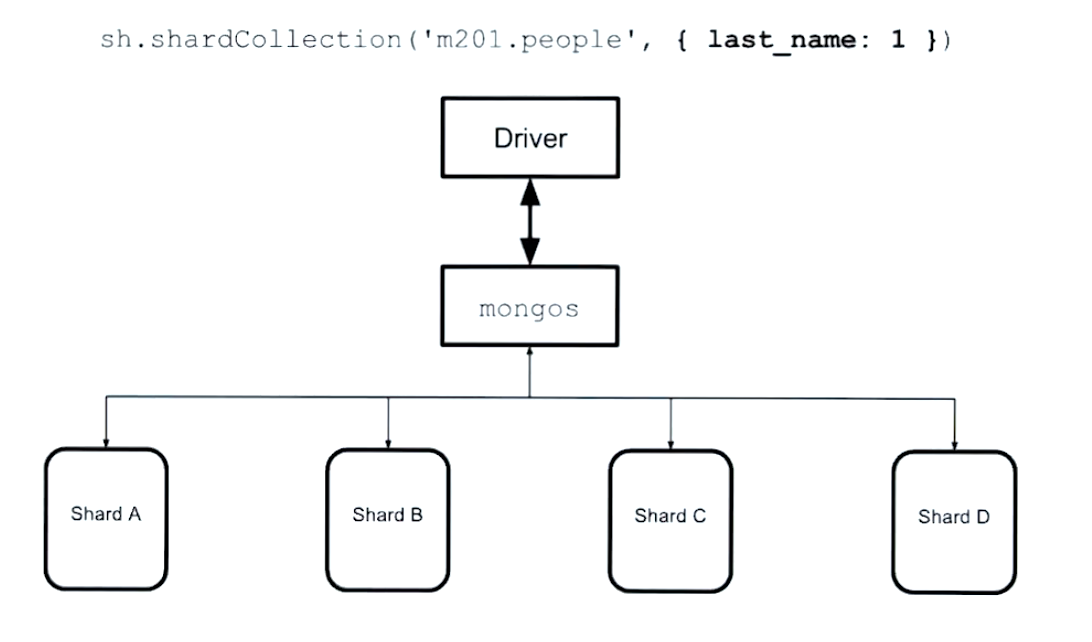
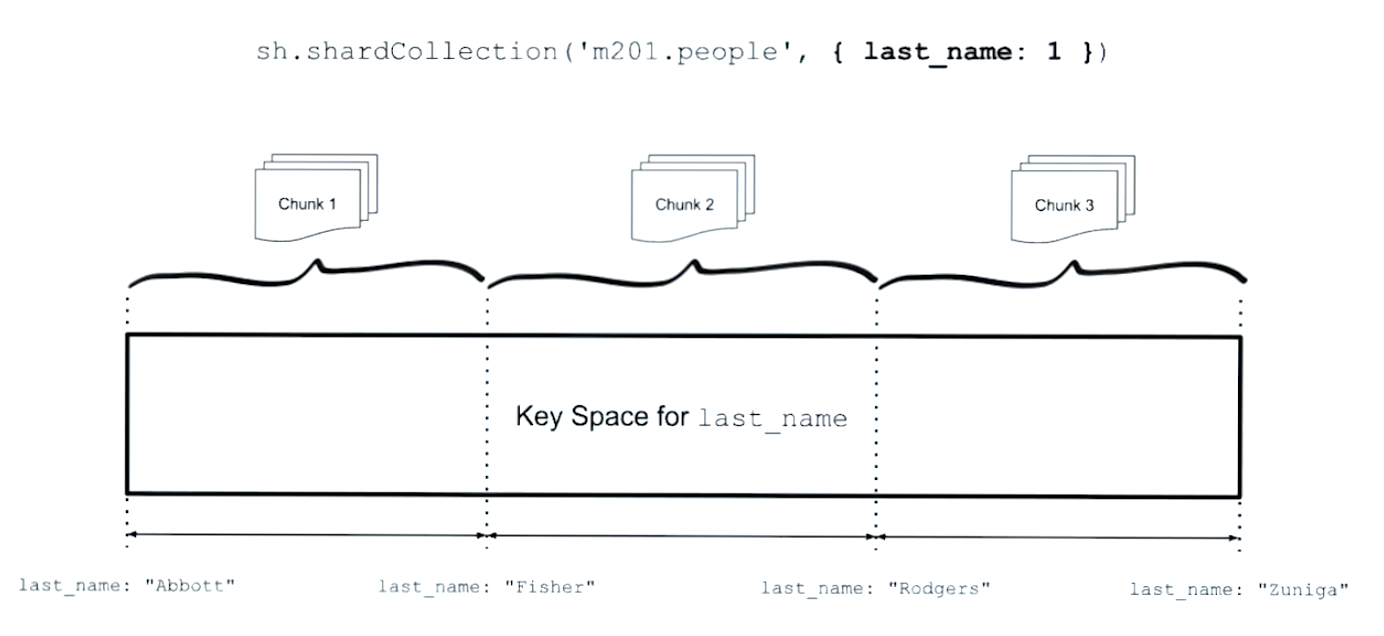
- Sharding works by defining key based ranges - our shard key
- It’s important to get a good shard key
Performance Considerations in Distributed Systems Part 2
- Scatter Gather and Routed Queries
- Sorting, limit & skip
Increasing Write Performance with Sharding Part 1
- Vertical vs. horizontal scaling
- Shard key rules
- Bulk writes
Shard Key Factors
- Cardinality(基数), high is better
- Frequency, even distributions
- Rate of change, avoid monotonically increasing or decreasing values.
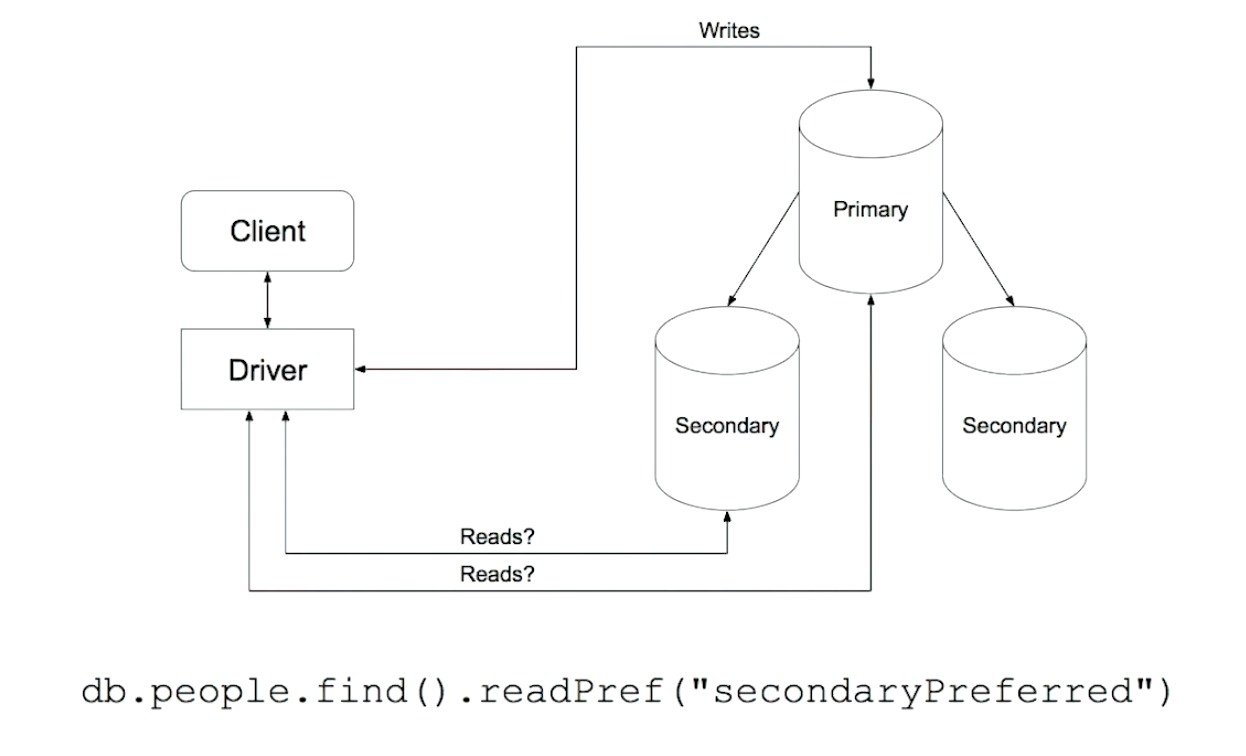
Reading from Secondaries
db.people.find().readPref("primary")
db.people.find().readPref("primaryPreferred")
db.people.find().readPref("secondary")
db.people.find().readPref("secondaryPreferred")
db.people.find().readPref("nearest")
Two read practices
Analytics queries
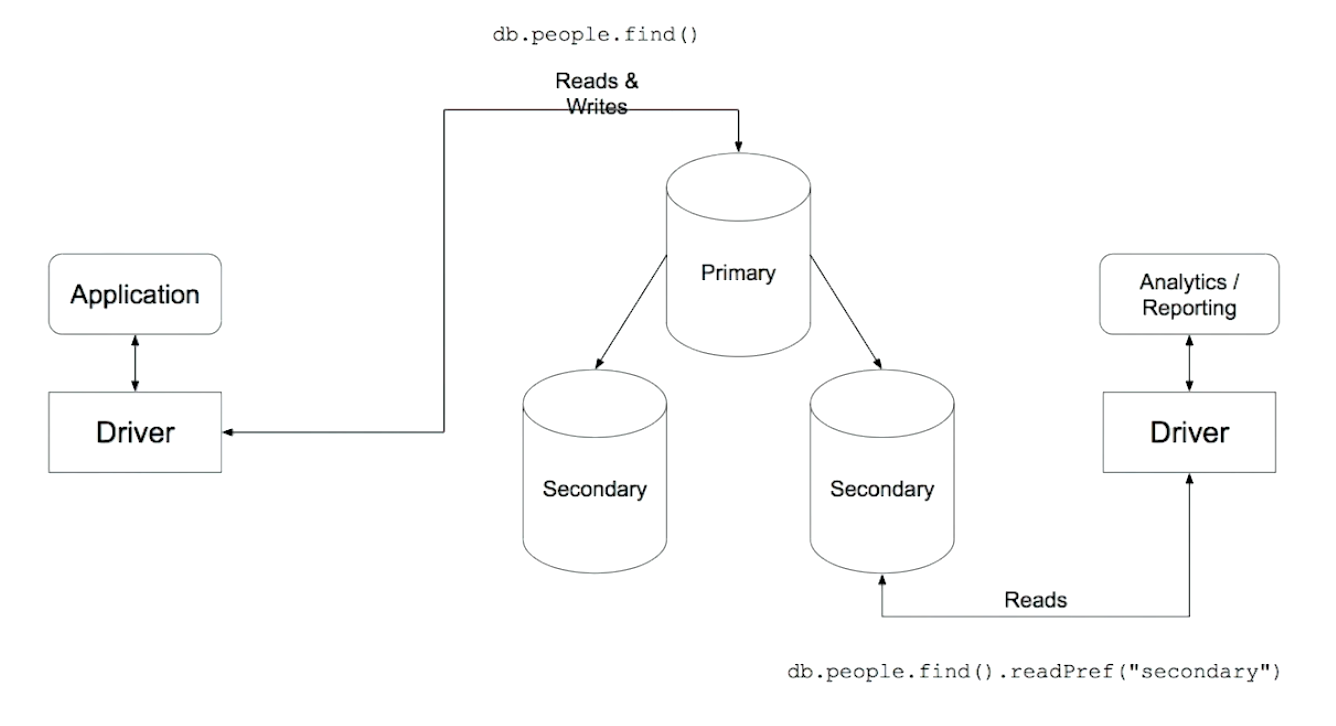
Local reads
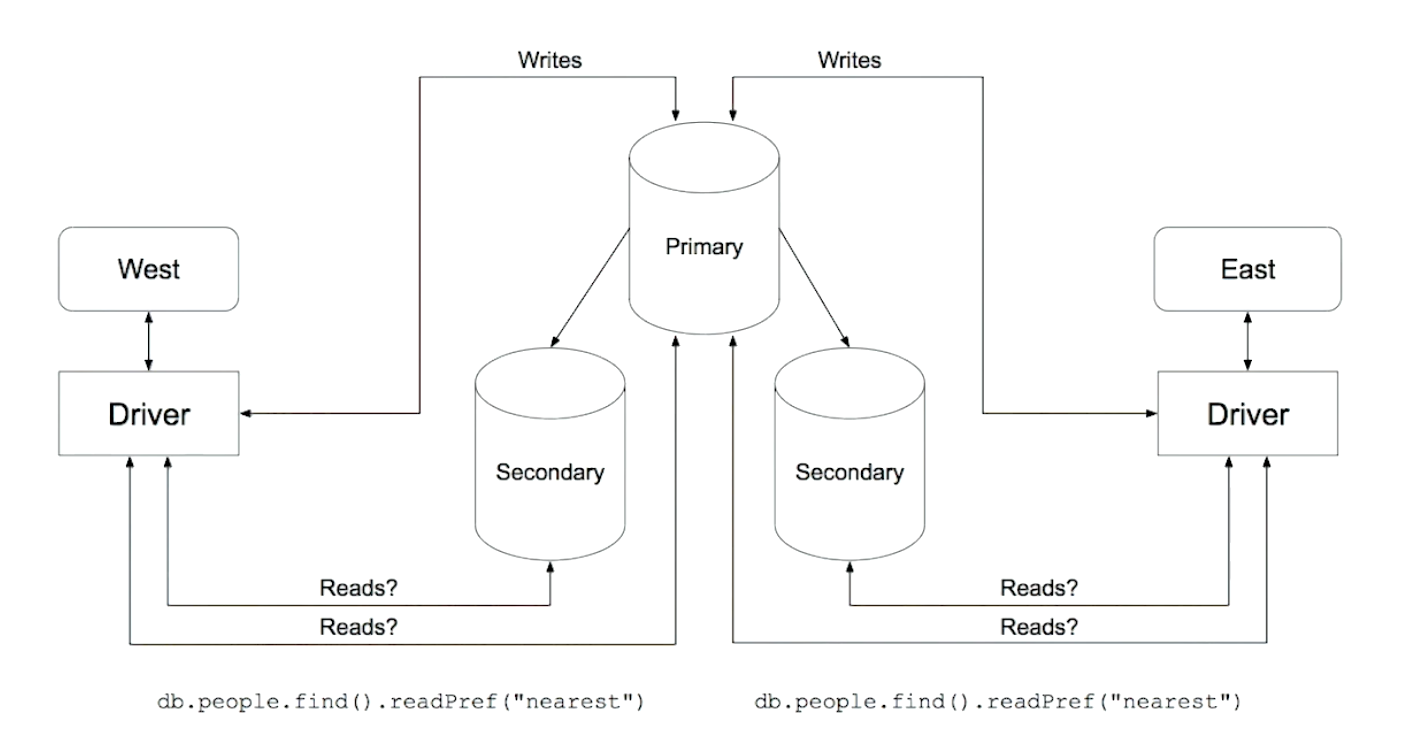
When Reading from a Secondary is a Bad idea
- Providing extra capacity for reads
Replica Sets with Differing Indexes Part 1
- analytics
- reporting
- text search
Prevent such a secondary from becoming primary
- Priority = 0
- Hidden Node
- Delayed Secondary
// after connecting to the first member, initiate the replica set
var conf = {
"_id": "M201",
"members": [
{ "_id": 0, "host": "127.0.0.1:27000" },
{ "_id": 1, "host": "127.0.0.1:27001" },
{ "_id": 2, "host": "127.0.0.1:27002", "priority": 0 },
]
};
rs.initiate(conf);
// confirm that the current member is primary, and that one has priority 0
rs.isMaster()
#!/usr/bin/env bash
# create directories for the different replica set members
mkdir -p /data/r{0,1,2}
# go into the configuration file directory
cd replicaset_configs
# checkout the ports our servers will be running on
grep 'port' *
# launch each member
mongod -f r0.cfg
mongod -f r1.cfg
mongod -f r2.cfg
# confirm all members are up and running
ps -ef | grep mongod
# connect to one of the members
mongo --port 27000
r0.cfg
net:
port: 27000
processManagement:
fork: true
systemLog:
destination: "file"
path: "/data/r0/log"
logAppend: true
storage:
dbPath: "/data/r0"
wiredTiger:
engineConfig:
cacheSizeGB: 0.5
replication:
oplogSizeMB: 10
replSetName: M201
r1.cfg
net:
port: 27001
processManagement:
fork: true
systemLog:
destination: "file"
path: "/data/r1/log"
logAppend: true
storage:
dbPath: "/data/r1"
wiredTiger:
engineConfig:
cacheSizeGB: 0.5
replication:
oplogSizeMB: 10
replSetName: M201
r2.cfg
net:
port: 27002
processManagement:
fork: true
systemLog:
destination: "file"
path: "/data/r2/log"
logAppend: true
storage:
dbPath: "/data/r2"
wiredTiger:
engineConfig:
cacheSizeGB: 0.5
replication:
oplogSizeMB: 10
replSetName: M201
Replica Sets with Differing Indexes Part 2
#!/usr/bin/env bash
# load the restaurants dataset to each member
mongoimport --host M201/localhost:27001,localhost:27002,localhost:27000 -d m201 -c restaurants restaurants.json
# connect to the replica set
mongo --host M201/localhost:27001,localhost:27002,localhost:27000
// on the primary, create an index
db.restaurants.createIndex({"name": 1})
// on the primary, confirm that the query uses the index
db.restaurants.find({name: "Perry Street Brasserie"}).explain()
// connect to the secondary with priority 0
db = connect("127.0.0.1:27002/m201")
// enable secondary reads
db.setSlaveOk()
// confirm that the same winning plan (using the index) happens on the secondary
db.restaurants.find({name: "Perry Street Brasserie"}).explain()
Replica Sets with Differing Indexes Part 3
#!/usr/bin/env bash
# after shutting down the secondary with priority 0 restart it as a standalone
mongod --port 27002 --dbpath /data/r2 --logpath /data/r2/standalone.log --fork
# connect to the member
mongo --port 27002
# after shutting down the server again, restart it with it's original config
mongod -f r2.cfg
# reconnect to the replica set
mongo --host M201/localhost:27001,localhost:27002,localhost:27000
// shutdown the secondary with priority 0
use admin
db.shutdownServer()
// after reconnecting to the standalone node, confirm that it's standalone
rs.status()
// switch to the m201 database
use m201
// create a new index
db.restaurants.createIndex({ "cuisine": 1, "address.street":1, "address.city": 1, "address.state": 1, "address.zipcode": 1 })
// run a query that will use the new index
db.restaurants.find({ cuisine: /Medi/, "address.zipcode": /6/ }).explain()
// shutdown the server again
use admin
db.shutdownServer()
// on the primary, rerun the last query (doesn't use our index)
db.restaurants.find({ cuisine: /Medi/, "address.zipcode": /6/ }).explain()
// connect to our passive node
db = connect("127.0.0.1:27002/m201")
// enable secondary reads
db.setSlaveOk()
// confirm that we can still use the new index on the secondary
db.restaurants.find({ cuisine: /Medi/, "address.zipcode": /6/ }).explain()
Problem
Which of the following conditions apply when creating indexes on secondaries?
- A secondary should never be allowed to become primary
True! If we were to allow it to become primary our application will experience the different set of indexes, once it becomes primary. That will potentially affect your application’s expected performance.
- These indexes can only be set on secondary nodes
False! The indexes can be set on the primary node, however we avoid doing so to prevent any impact on the operational workload, since these only service an analytical workload.
- We can create specific indexes on secondaries, even if they are not running in standalone mode
False! No we first need to safely shutdown the secondary, and then restart it in standalone mode before we can create an index on it.
Aggregation Pipeline on a Sharded Cluster



What operators will cause a merge stage on the primary shard for a database?
$out$lookup
Final
Which of the following statements is/are true?
It’s common practice to co-locate your mongos on the same machine as your application to reduce latency. Collations can be used to create case insensitive indexes. By default, all MongoDB user-created collections have an _id index.
Q7
Problem:
Given the following indexes:
{ categories: 1, price: 1 }
{ in_stock: 1, price: 1, name: 1 }
The following documents:
{ price: 2.99, name: "Soap", in_stock: true, categories: ['Beauty', 'Personal Care'] }
{ price: 7.99, name: "Knife", in_stock: false, categories: ['Outdoors'] }
And the following queries:
db.products.find({ in_stock: true, price: { $gt: 1, $lt: 5 } }).sort({ name: 1 })
db.products.find({ in_stock: true })
db.products.find({ categories: 'Beauty' }).sort({ price: 1 })
Which of the following is/are true?
Let’s examine each of these choices:
Index #1 would provide a sort to query #3.
Yes, that is correct.
Index #2 properly uses the equality, sort, range rule for query #1.
No, if we were to build an index for query #1 using the equality, sort, range rule, then the index would be: { in_stock: 1, name: 1, price: 1 }
There would be a total of 4 index keys created across all of these documents and indexes.
No, there would be 5 total index keys:
{ categories: 'Beauty', price: 2.99 }
{ categories: 'Personal Care', price: 2.99 }
{ categories: 'Outdoors', price: 7.99 }
{ in_stock: true, price: 2.99, name: 'Soap' }
{ in_stock: false, price: 7.99, name: 'Knife'}
The additional index keys are due to the multikey index on categories.
Index #2 can be used by both query #1 and #2.
Yes, that is correct.