Replication(复制) vs Sharding(分片)
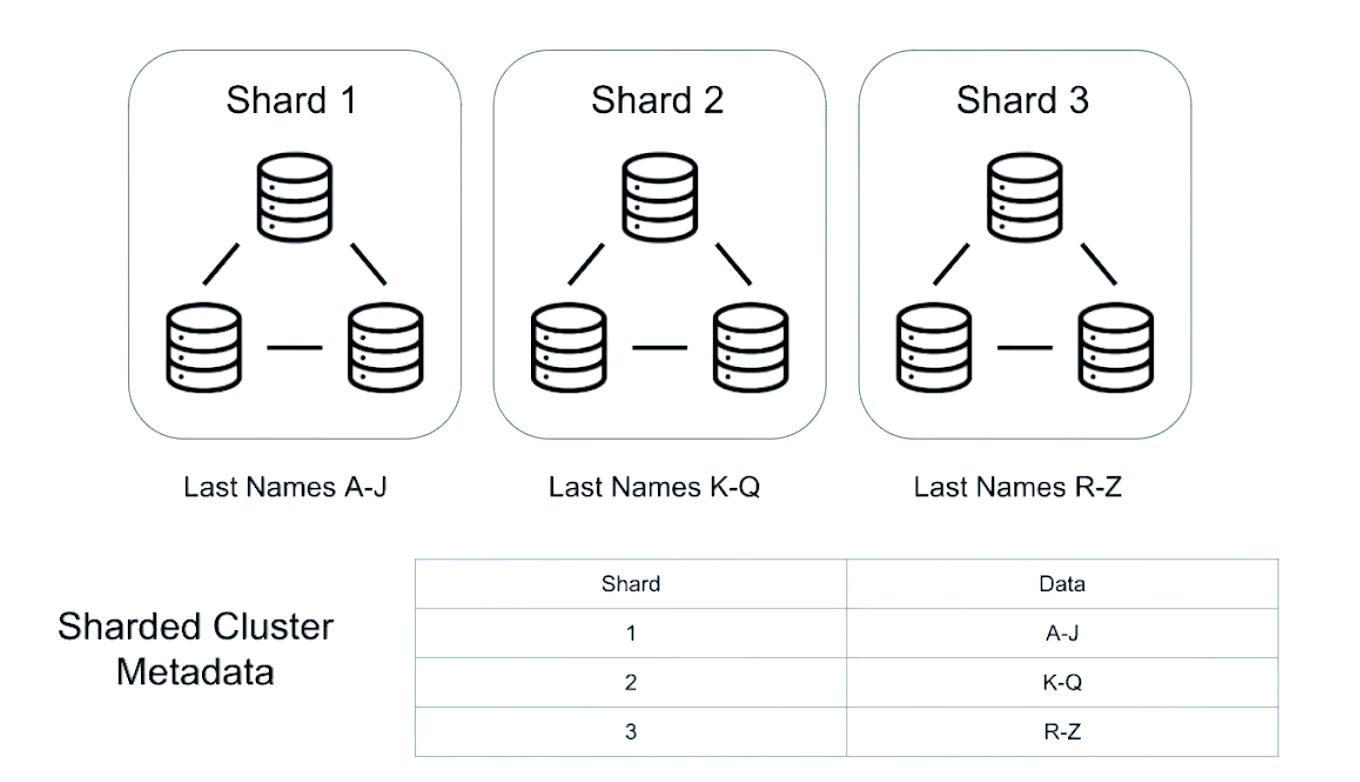
复制让多台服务器拥有同样的数据副本,每一台服务器都是其他服务器的镜像,而每一个分片都有其他分片拥有不同的数据子集。
分片的目标之一是创建一个拥有多个实例(或多台机器)的目标集群,整个集群对应用程序来说就像是一台单机服务器。
为了对应用程序隐藏数据库架构的细节,在分片之前要先执行mongos进行一次路由过程。
misc
insert some data
for (var i = 0; i< 100000; i++) {
db.users.insert({"username": "user"+i, "created_at": new Date()});
}
What is Sharding?
A server in a replica set stores the whole database, it can not be vertically scaled forever.
Sharding is for horizontall scaling, just cuting big database into pieces. Replication saves the single point failure and guarantees high availability.
Sharding is horizontal scaling.
Sharding allows us to grow our dataset without worrying about being able to store it all on one server.
In MongoDB, scaling is done horizontally, which means instead of making the individual machines better, we just add more machines and then distribute the dataset among those machines.
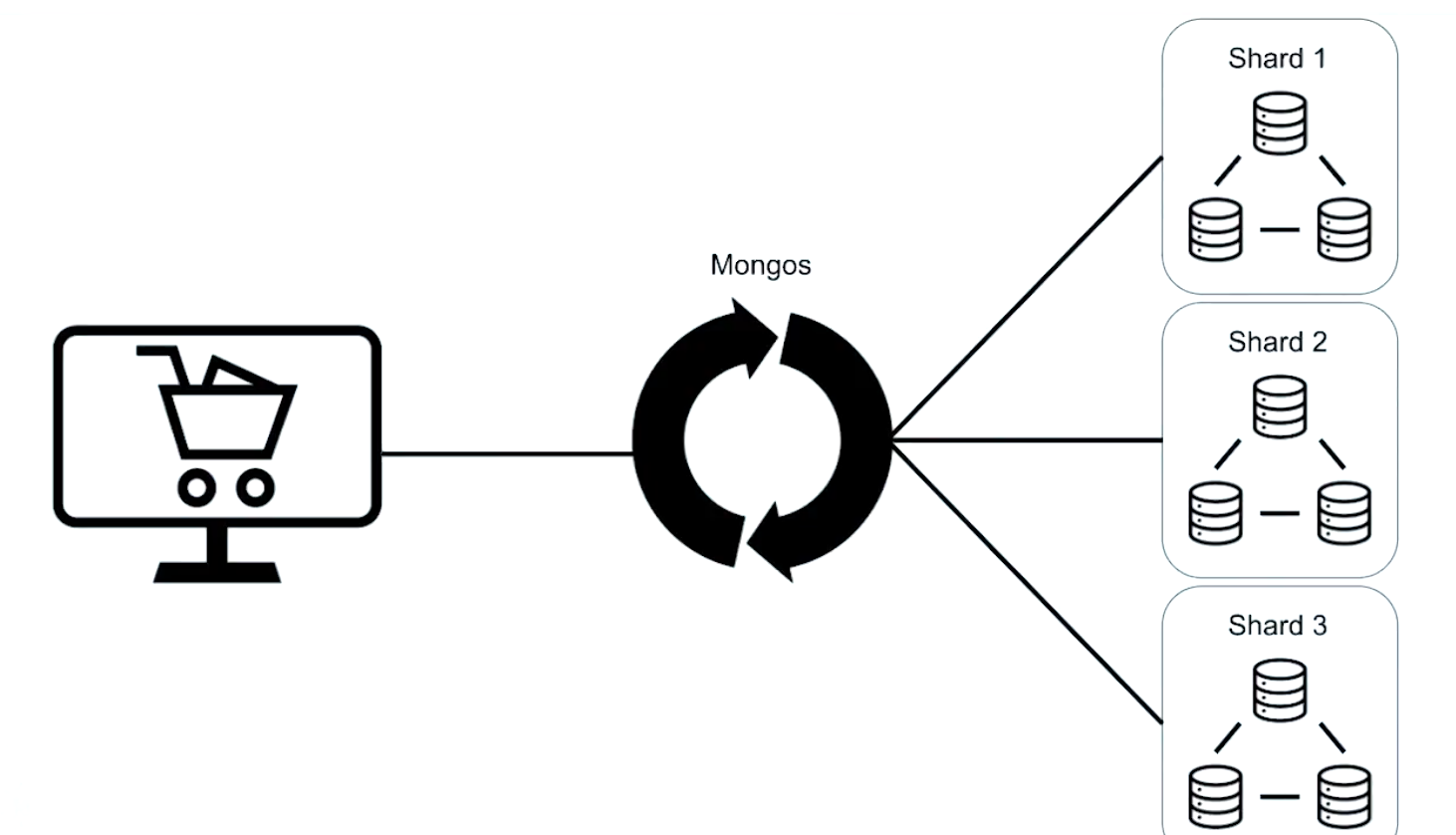
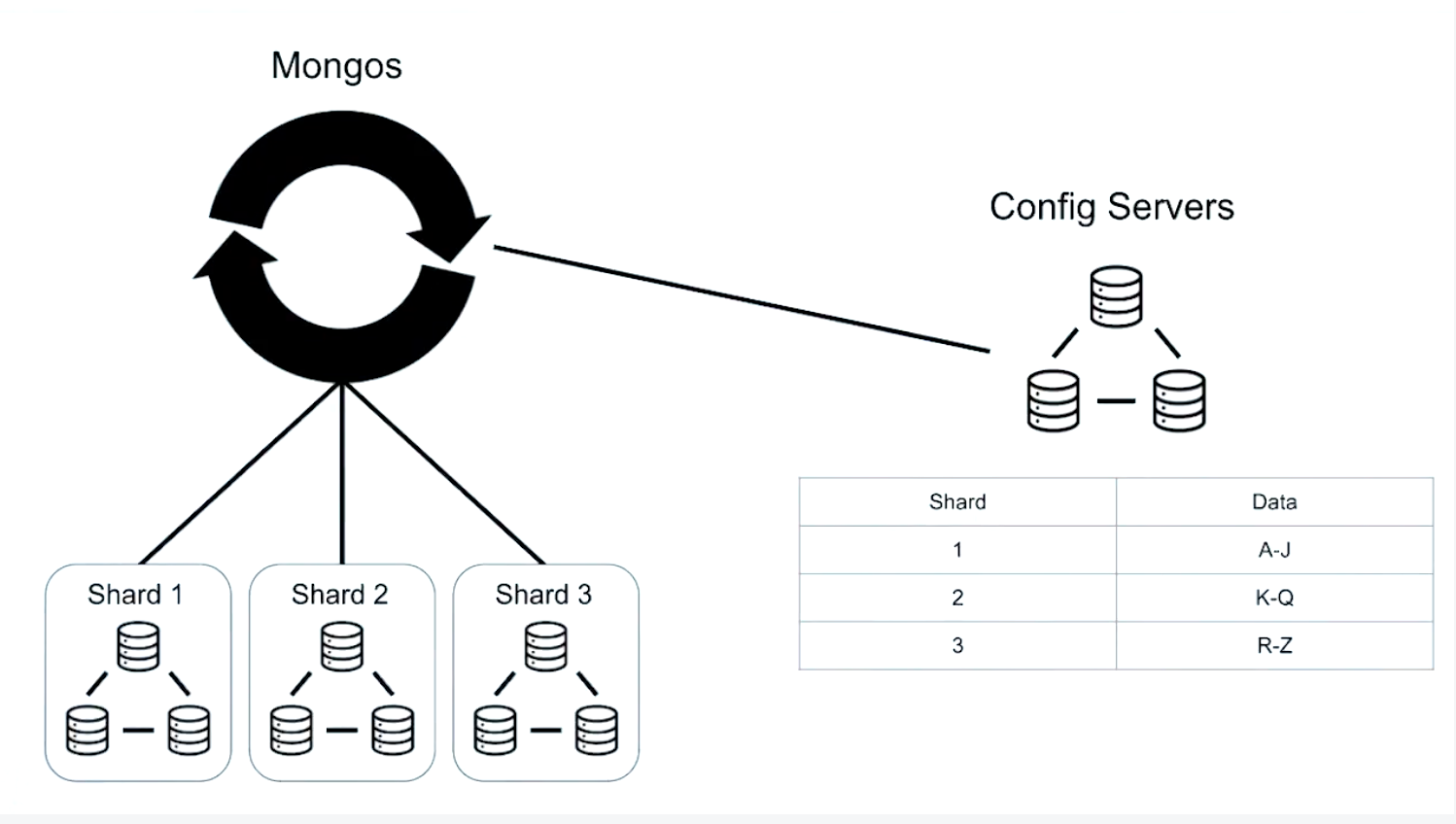
That router process is called the Mongos. And clients connect to Mongos us instead of connecting to each shard individually. And we have any number of Mongos processes so we can service many different applications or requests to the same Sharded Cluster.

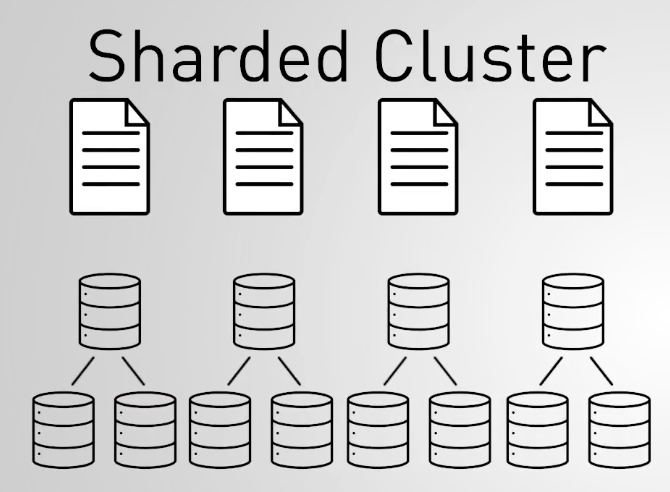
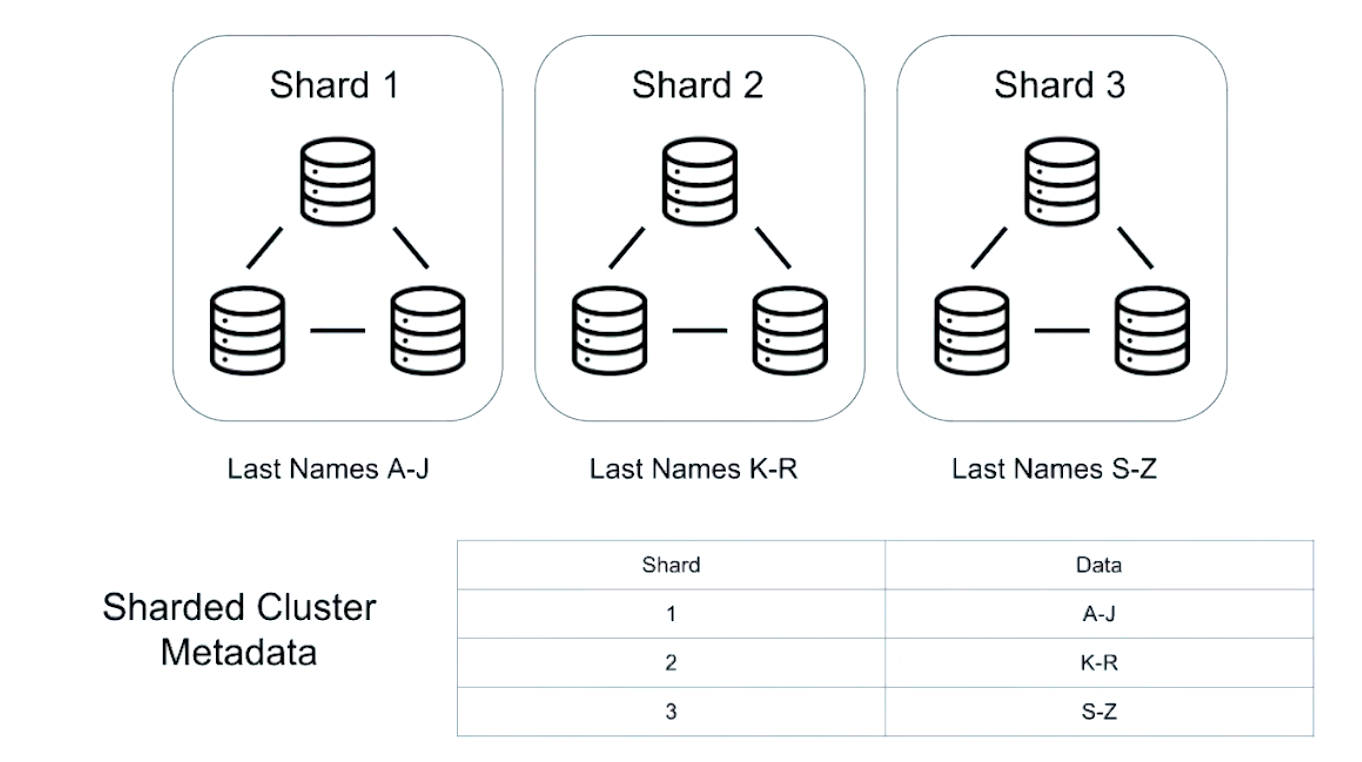
- Shards: store distributed collections
- Config Servers (Config Server Replica Set): store metadata about each shard
- Mongos: routes queries to shards
When to Shard

stay tuned for that 请继续关注
Zone sharding(geographically)
We should consider sharding when:
Our organization outgrows the most powerful servers available, limiting our vertical scaling options. This is correct - sharding can provide an alternative to vertical scaling.
Government regulations require data to be located in a specific geography. This is correct - sharding allows us to store different pieces of data in specific countries or regions.
We are holding more than 5TB per server and operational costs increase dramatically. This is correct - generally, when our deployment reaches 2-5TB per server, we should consider sharding.
Sharding Architecture

Setting Up a Sharded Cluster
What we need to do?
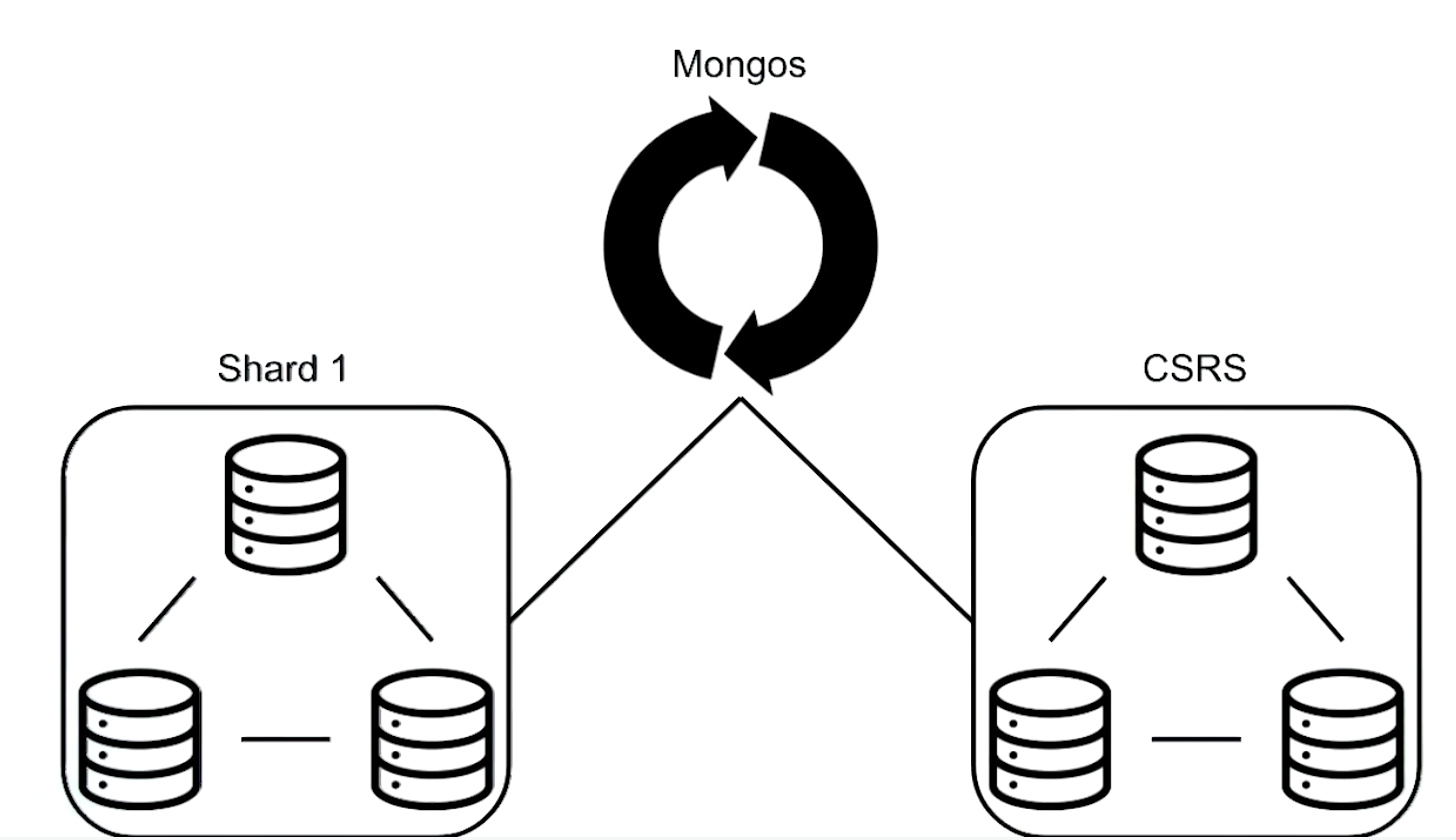
- build a CSRS (a config server replica set)
- build mongos
- connect mongos and config server with replica set together
If you’d like to deploy a sharded cluster on your machine, you can find the commands from the lecture here:
Configuration file for first config server csrs_1.conf:
sharding:
clusterRole: configsvr
replication:
replSetName: m103-csrs
security:
keyFile: /var/mongodb/pki/m103-keyfile
net:
bindIp: localhost,192.168.103.100
port: 26001
systemLog:
destination: file
path: /var/mongodb/db/csrs1.log
logAppend: true
processManagement:
fork: true
storage:
dbPath: /var/mongodb/db/csrs1
csrs_2.conf:
sharding:
clusterRole: configsvr
replication:
replSetName: m103-csrs
security:
keyFile: /var/mongodb/pki/m103-keyfile
net:
bindIp: localhost,192.168.103.100
port: 26002
systemLog:
destination: file
path: /var/mongodb/db/csrs2.log
logAppend: true
processManagement:
fork: true
storage:
dbPath: /var/mongodb/db/csrs2
csrs_3.conf:
sharding:
clusterRole: configsvr
replication:
replSetName: m103-csrs
security:
keyFile: /var/mongodb/pki/m103-keyfile
net:
bindIp: localhost,192.168.103.100
port: 26003
systemLog:
destination: file
path: /var/mongodb/db/csrs3.log
logAppend: true
processManagement:
fork: true
storage:
dbPath: /var/mongodb/db/csrs3
Starting the three config servers:
mongod -f csrs_1.conf
mongod -f csrs_2.conf
mongod -f csrs_3.conf
Connect to one of the config servers:
mongo --port 26001
Initiating the CSRS:
rs.initiate()
Creating super user on CSRS:
use admin
db.createUser({
user: "m103-admin",
pwd: "m103-pass",
roles: [
{role: "root", db: "admin"}
]
})
Authenticating as the super user:
db.auth("m103-admin", "m103-pass")
Add the second and third node to the CSRS:
rs.add("192.168.103.100:26002")
rs.add("192.168.103.100:26003")
Mongos config (mongos.conf):
sharding:
configDB: m103-csrs/192.168.103.100:26001,192.168.103.100:26002,192.168.103.100:26003
security:
keyFile: /var/mongodb/pki/m103-keyfile
net:
bindIp: localhost,192.168.103.100
port: 26000
systemLog:
destination: file
path: /var/mongodb/db/mongos.log
logAppend: true
processManagement:
fork: true
Start the mongos server:
mongos -f mongos.conf
Connect to mongos:
mongo --port 26000 --username m103-admin --password m103-pass --authenticationDatabase admin
Check sharding status:
MongoDB Enterprise mongos> sh.status()
Updated configuration for node1.conf:
sharding:
clusterRole: shardsvr
storage:
dbPath: /var/mongodb/db/node1
wiredTiger:
engineConfig:
cacheSizeGB: .1
net:
bindIp: 192.168.103.100,localhost
port: 27011
security:
keyFile: /var/mongodb/pki/m103-keyfile
systemLog:
destination: file
path: /var/mongodb/db/node1/mongod.log
logAppend: true
processManagement:
fork: true
replication:
replSetName: m103-repl
Updated configuration for node2.conf:
sharding:
clusterRole: shardsvr
storage:
dbPath: /var/mongodb/db/node2
wiredTiger:
engineConfig:
cacheSizeGB: .1
net:
bindIp: 192.168.103.100,localhost
port: 27012
security:
keyFile: /var/mongodb/pki/m103-keyfile
systemLog:
destination: file
path: /var/mongodb/db/node2/mongod.log
logAppend: true
processManagement:
fork: true
replication:
replSetName: m103-repl
Updated configuration for node3.conf:
sharding:
clusterRole: shardsvr
storage:
dbPath: /var/mongodb/db/node3
wiredTiger:
engineConfig:
cacheSizeGB: .1
net:
bindIp: 192.168.103.100,localhost
port: 27013
security:
keyFile: /var/mongodb/pki/m103-keyfile
systemLog:
destination: file
path: /var/mongodb/db/node3/mongod.log
logAppend: true
processManagement:
fork: true
replication:
replSetName: m103-repl
Connecting directly to secondary node (note that if an election has taken place in your replica set, the specified node may have become primary):
mongo --port 27012 -u "m103-admin" -p "m103-pass" --authenticationDatabase "admin"
Shutting down node:
use admin
db.shutdownServer()
Restarting node with new configuration:
mongod -f node2.conf
Stepping down current primary:
rs.stepDown()
Adding new shard to cluster from mongos:
sh.addShard("m103-repl/192.168.103.100:27012")
Recap
- Launching mongos and CSRS
- Enabling sharding on a RS
- Rolling upgrade!
- Adding shards to a cluster
Starting processes order
We can not start mongod before CSRS Servers and mongos are started.
- start all CSRS server
- start mongos
- start mongod replica set
501 1938 1 0 9:46AM ?? 0:07.58 mongod -f etc/node1.yaml
501 2043 1 0 9:49AM ?? 0:04.83 mongod -f etc/node2.yaml
501 2085 1 0 9:49AM ?? 0:02.83 mongod -f etc/csrs_1.yaml
501 2088 1 0 9:50AM ?? 0:03.01 mongod -f etc/csrs_2.yaml
501 2091 1 0 9:50AM ?? 0:02.92 mongod -f etc/csrs_3.yaml
501 2113 1 0 9:50AM ?? 0:04.11 mongod -f etc/node3.yaml
Tips
- Mongos inherits its users from the config servers.
- The mongos configuration file needs to specify the config servers.
- The mongos configuration file doesn’t need to have a dbpath.
Lab: Deploy a Sharded Cluster
Config DB
You should generally never write data to it.
connect to mongos
sh.status()
If you’d like to explore the collections on the config database, you can find the instructions here:
Switch to config DB:
use config
Query config.databases:
db.databases.find().pretty()
Query config.collections:
db.collections.find().pretty()
Query config.shards:
db.shards.find().pretty()
Query config.chunks:
db.chunks.find().pretty()
Query config.mongos:
db.mongos.find().pretty()
When should you manually write data to the Config DB? When directed to by MongoDB documentation or Support Engineers
Shard Keys
Shard key is an indexed field in a collection which you want to slice it into data pieces.
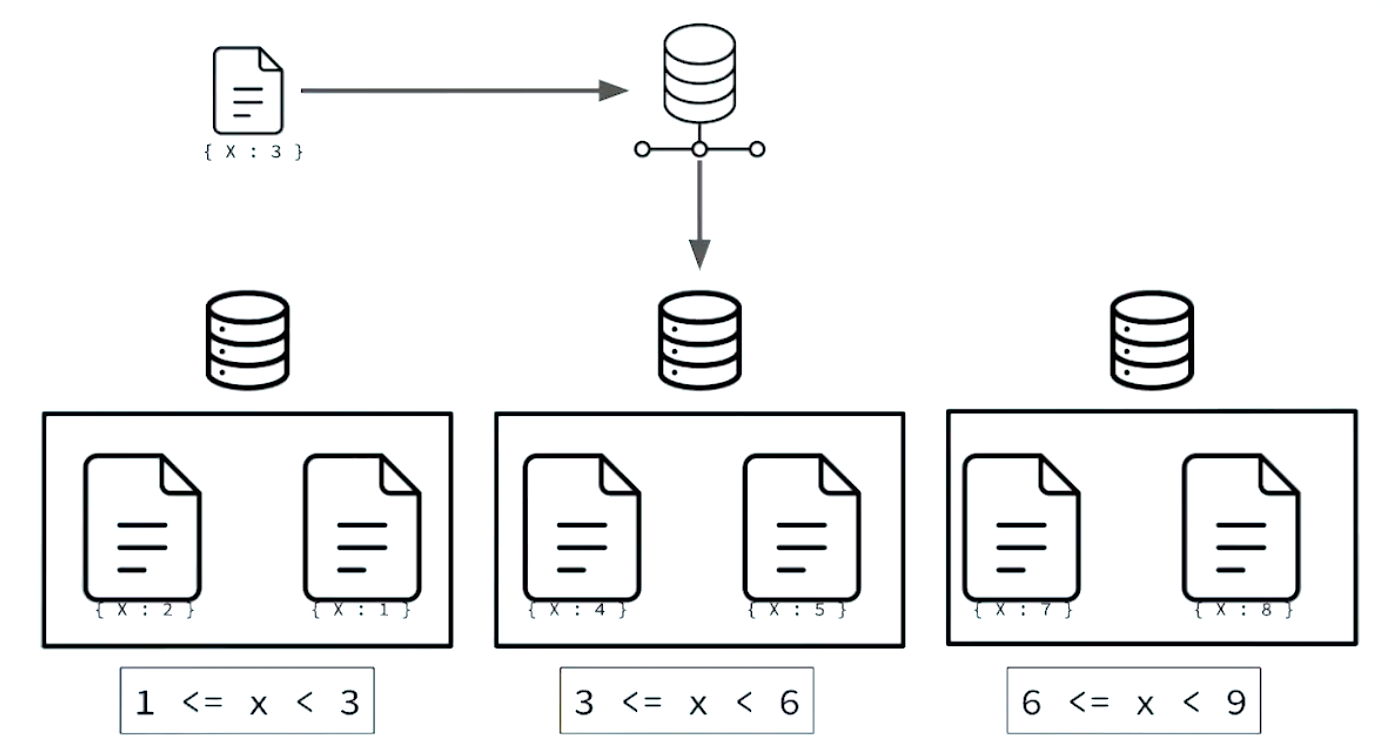

- Shard key must be incluede in every collection.
- Shard key fields must be indexed
- Shard keys are immutable
- Shard keys are permanent

If you’d like to shard a collection, you can find instructions to create a shard key here:
Show collections in m103 database:
use m103
show collections
Enable sharding on the m103 database:
sh.enableSharding("m103")
Find one document from the products collection, to help us choose a shard key:
db.products.findOne()
Create an index on sku:
db.products.createIndex( { "sku": 1 } )
Shard the products collection on sku:
sh.shardCollection( "m103.products", { "sku": 1 } )
Checking the status of the sharded cluster:
sh.status()
Recap
- Shard Keys determine data distribution in a sharded cluster
- Shard Keys are immutable
- Shard Key Values are immutable
- Create the underlying index first before sharding on the indexed field or fields
- Shard keys are used to route queries to specific shards
Picking a Good Shard Key
Unsharding is hard.
cardinality 基数

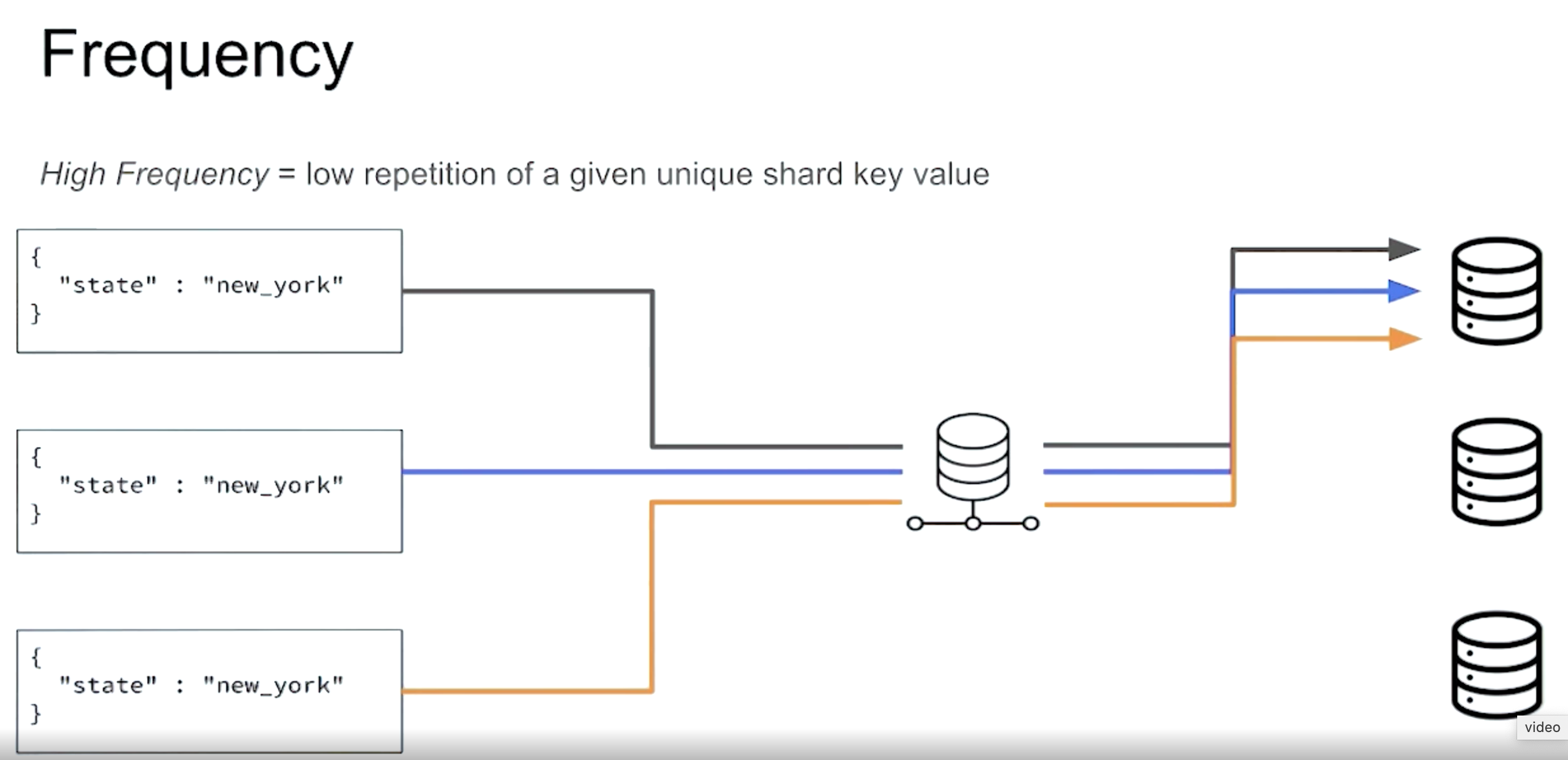
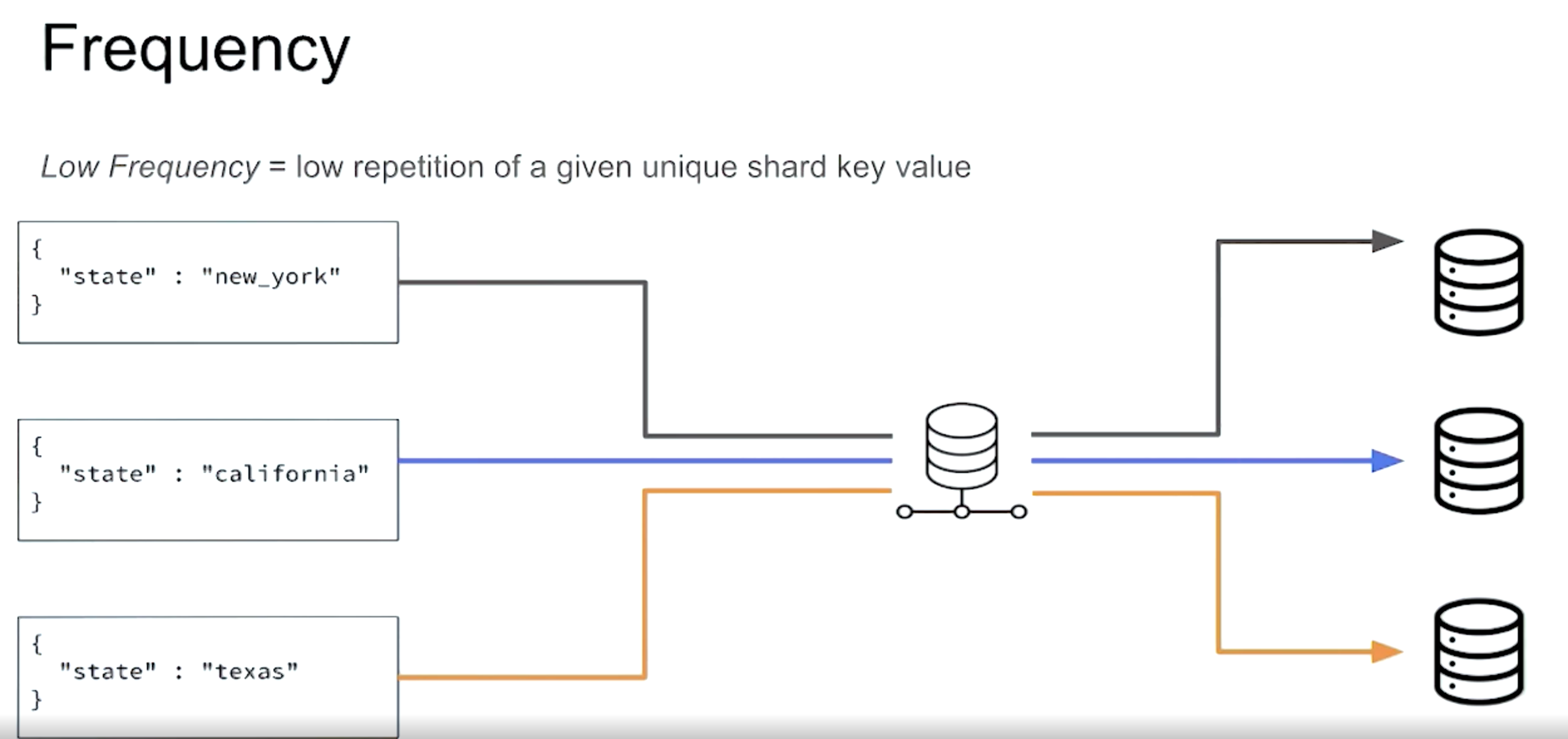



Problem:
Which of the following are indicators that a field or fields are a good shard key choice?
- High Cardinality
- Low Frequency
- Non-monotonic change
Hashed Shard Keys
Addtional type of shard key. Hashed shard keys, which underline index is hashed.
More even distributed data.



Lab: Shard a Collection
Import json data
mongoimport --port=26000 --host=localhost --authenticationDatabase=admin -u m103-admin -p m103-pass --db m103 --collection products --file /dataset/products.json
Connet to mongos
mongo --port 26000 --username m103-admin --password m103-pass --authenticationDatabase admin
Create an index on sku:
db.products.createIndex( { "sku": 1 } )
Shard the products collection on sku:
sh.shardCollection( "m103.products", { "sku": 1 } )
Checking the status of the sharded cluster:
sh.status()
Chunks
MongoDB uses the shard key associated to the collection to partition the data into chunks. A chunk consists of a subset of sharded data. Each chunk has a inclusive lower and exclusive upper range based on the shard key.
// connect to mongos
use config
db.chunks.findOne()
1MB <= chunks size <= 1024MB
Chunk ranges have an inclusive minimum and an exclusive maximum.
Balancing
Start the balancer:
sh.startBalancer(timeout, interval)
Stop the balancer:
sh.stopBalancer(timeout, interval)
Enable/disable the balancer:
sh.setBalancerState(boolean)

Queries in a Sharded Cluster
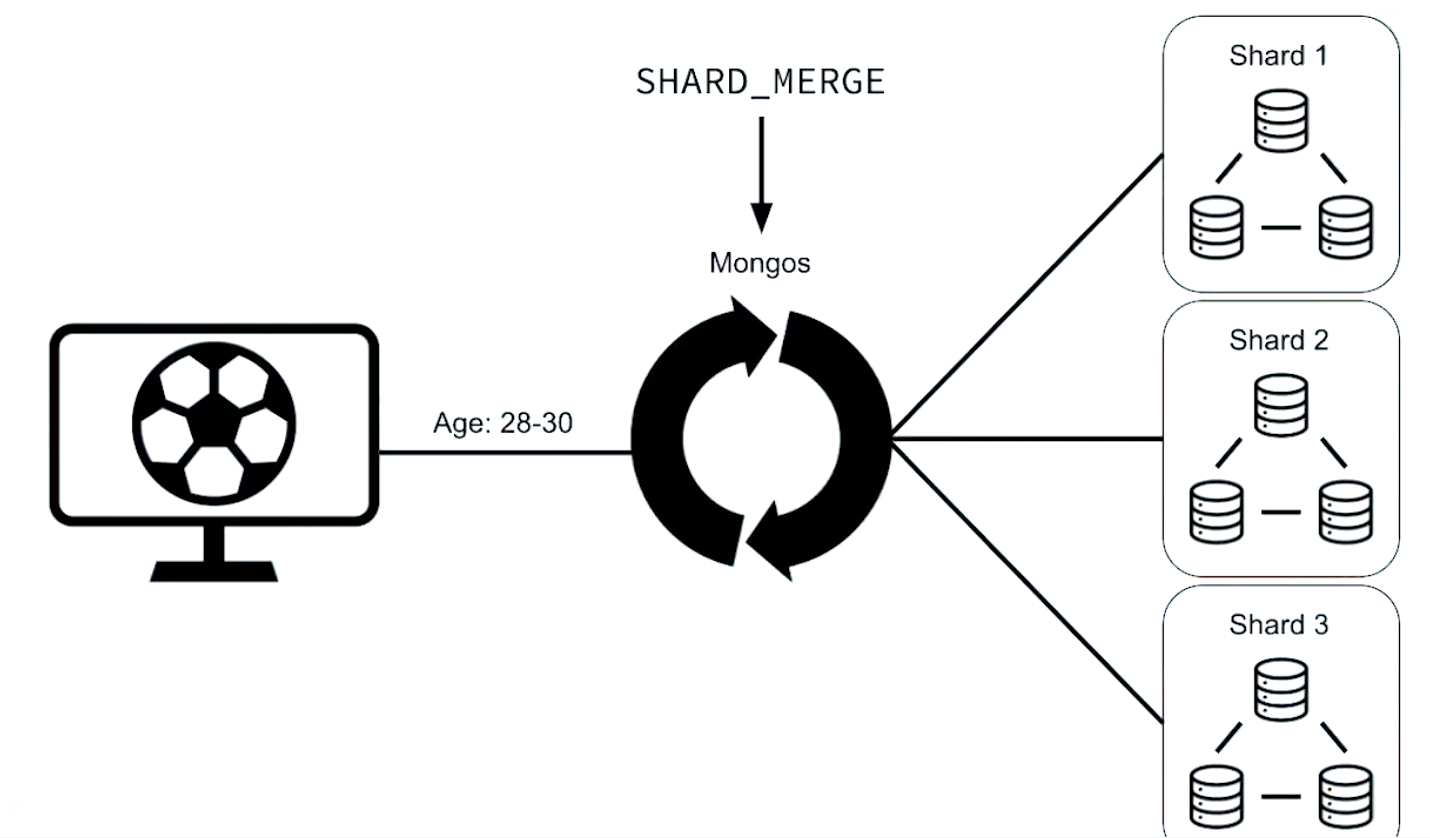
targeted vs scatter-gathered (集中收集或分散收集)


Targeted Queries vs Scatter Gather: Part 1
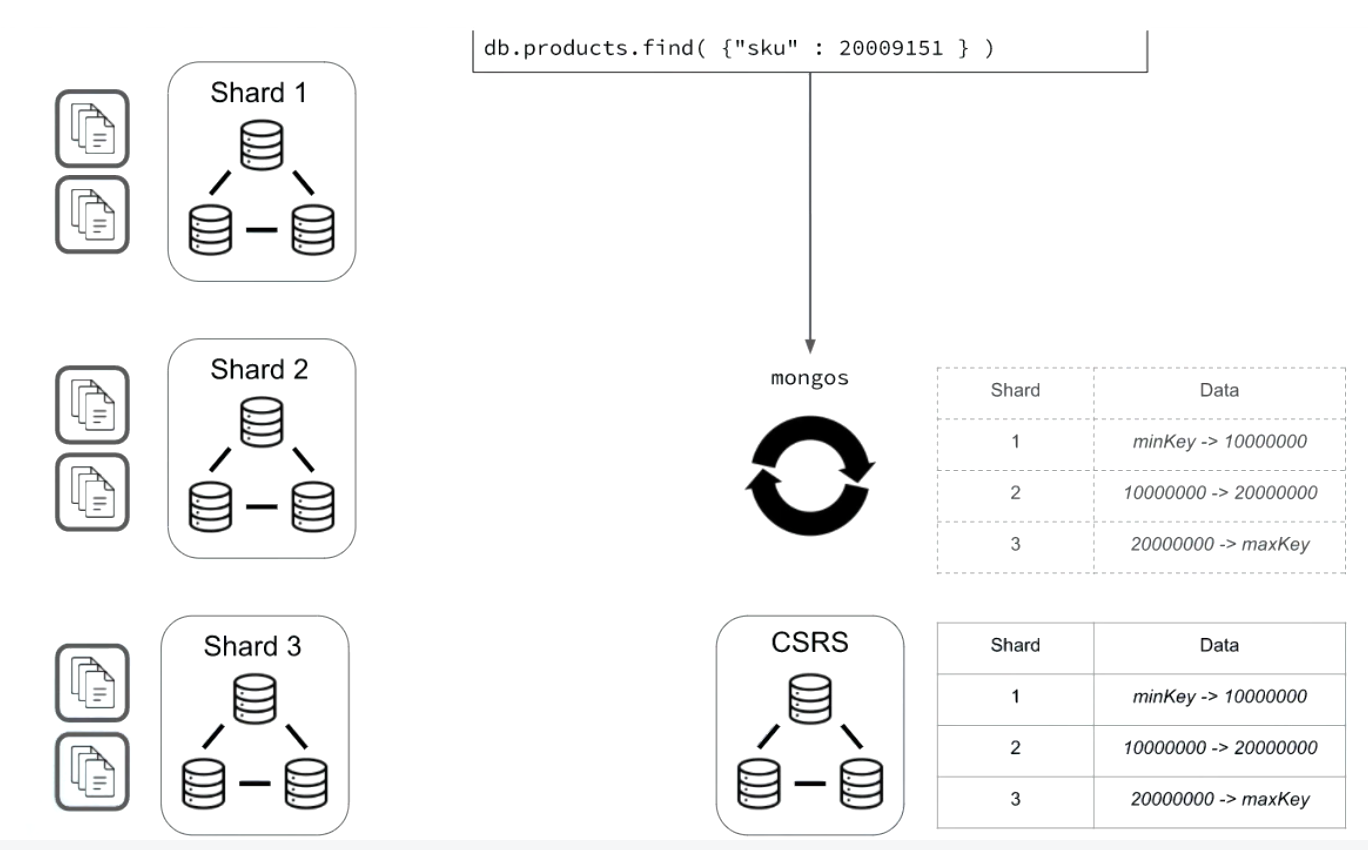

Targeted Queries vs Scatter Gather: Part 2

Show collections in the m103 database:
use m103
show collections
Targeted query with explain() output:
db.products.find({"sku" : 1000000749 }).explain()
Scatter gather query with explain() output:
db.products.find( {
"name" : "Gods And Heroes: Rome Rising - Windows [Digital Download]" }
).explain()
Problem
Given a collection that is sharded on the following shard key:
{ "sku" : 1, "name" : 1 }
Which of the following queries results in a targeted query?
db.products.find( { "sku" : 1337, "name" : "MongoHacker" } )
db.products.find( { "name" : "MongoHacker", "sku" : 1337 } )
This is correct.
These two queries are actually identical, and can both be targeted using the shard key.
db.products.find( { "sku" : 1337 } )
This query includes the sku prefix and can therefore be targeted.
Lab: Detect Scatter Gather Queries
Which of the following is required in order for a query to be targeted to a subset of shards?
- The query uses the shard key
- An index exists on the shard key
in order for a query to be targeted to a subset of shards, the query must use the shard key. This is because the data itself is divided on the shard key, so without that parameter the server cannot locate data without doing a Scatter Gather query.
in order for a query to be targeted to a subset of shards, an index must exist on the shard key. This is required before the collection can be sharded.
Problems
Given the following replica set configuration:
conf = {
"_id": "replset",
"version": 1,
"protocolVersion": 1,
"members": [
{
"_id": 0,
"host": "localhost:27017",
"priority": 1,
"votes": 1
},
{
"_id": 1,
"host": "localhost:27018",
"priority": 1,
"votes": 1
},
{
"_id": 2,
"host": "localhost:27019",
"priority": 1,
"votes": 1
},
{
"_id": 3,
"host": "localhost:27020",
"priority": 0,
"votes": 0,
"slaveDelay": 3600
}
]
}
It serves as a “hot” backup of data in case of accidental data loss on the other members, like a DBA accidentally dropping the database.
Given the following shard key:
{ "country": 1, "_id": 1 }
Which of the following queries will be routed (targeted)? Remember that queries may be routed to more than one shard.
The correct answers are:
db.customers.find({"country": "Norway", "_id": 54})
This specifies both indexes used in the shard key.
db.customers.find({"country": { $gte: "Portugal", $lte: "Spain" }})
This specifies a prefix of the indexes used in the shard key, “country”, and will be routed to shards containing the necessary information.
db.customers.find({"_id": 914, "country": "Sweden"})
Although the indexes are specified in reverse order, this is a routed query. Any document matching {"_id": 914, “country”: “Sweden”} must be identical to {“country”: “Sweden”, “_id”: 914}. The query planner will take advantage of this and reorder the fields.
The incorrect answer is:
db.customers.find({"_id": 455})
Because the neither a prefix nor the full shard key is provided, mongos has no way to determine how to appropriately route this query. Instead, it will send this query to all shards in the cluster in a scatter-gather operation.